
(六)指向分析
程序分析中的敏感性
看到一篇总记得比较有条理的博客:华为云社区的《静态代码分析敏感性概念》,本小节(程序分析中的敏感性)的内容全部来自该博客,本人只做了排版优化。
本文介绍几种在静态代码分析中的敏感性分析的概念。主要有流敏感(flow-sensitive),路径敏感(path-sensitive),上下文敏感(context-sensitive)和域敏感(field-sensitive)。所有的敏感性分析相对于非敏感性分析,在分析的准确性上,都会有很大的精度提升(如减少漏报和误报等),但是会在时间或者空间上有更大损耗。
流敏感(flow-sensitive)
流敏感分析,是指在分析时,区分程序的执行顺序的分析。如下面的两段代码:
代码片段一:
1 | String name = "zhangsan"; |
代码片段二:
1 | String name = System.getProperty("name"); |
这里,我们设定 sqlExecute 是执行一条 sql 命令的方法,则上面的两个代码片段中,System.getProperty() 是从环境变量中获取数据,可以认为是污点入口。如果是代码片段一,可能发生 sql 注入风险,因为 name 在第 2 行,被赋给了一个外部传入的数据,第 3 行将 name 传递给了 sql,在第 4 行,sql 被传入一个污点坑。而代码片段二,则没有可能发生 sql 注入风险,因为在第 2 行,name 是个常量,第 3 行 sql 也没有被污染,是拼接了一个常量 zhangsan。
上面的分析,实际上是一种流敏感的分析,我们分析了 name 在第 1 行和第 2 行指向的内容,从而知道在代码片段一中,第 3 行的 name 指向一个污染数据,代码片段二中,第 3 行的 name 指向的是一个常量字符串,从而知道上面代码片段一有 sql 注入风险,代码片段二没有 sql 注入风险。而如果是流不敏感分析,则不管是代码片段一还是代码片段二,都只能得出来的一个结论是:第 3 行的 name 指向的是常量字符串或者是外部传入的污染数据,从而得到的结论是代码片段一和代码片段二都有 sql 注入的风险。
从上面的一个简单的结合指向分析和污点传播的案例,我们可以知道,流敏感分析可以有效降低分析的误报,提高分析的准确性。绝大部分的数据流分析,例如常量传播、指向分析等,都需要是流敏感分析,当然,也不是说所有的分析都需要是流敏感的,比如静态类型语言中,分析一个变量的类型,分析到一个位置的某个变量的类型信息后,其他地方的该变量自然就都是该类型的。
流敏感分析已经是程序分析中,数据流分析的最基本要求,已有的一些成熟的代码分析框架,例如 Java 中的 Soot 和 Wala,C/C++中的 Clang 等,都是原始支持流敏感的分析。
部分源码,在生成 SSA 形式的三地址码后,在 SSA 上的非流敏感分析,在相当程度上,也可以实现类似于普通三地址码的流敏感分析的效果,因为 SSA 中每个变量只会有一次赋值,生成 SSA 形式后,实际上的效果就是每个变量只会有一个指向,例如上面的代码片段,当针对 name 变量,针对两次赋值区分 name1 和 name2 之后,在 sql 中,都使用 name2 赋值,不会再有不同指向的问题。
路径敏感(path-sensitive)
路径敏感,就是在进行分析时,同时考虑了分支路径上面的条件信息。如下面的两段代码:
代码片段一:
1 | String name; |
代码片段二:
1 | String name; |
上面的两段代码除了 x 的取值外,都相同。那么来分析上面的代码。当 x 大于 0 时,name 是一个从环境变量里面获取的污点数据,当 x 小于等于 0 时,name 是一个常量 zhangsan,然后执行 sql 命令的拼接,并执行命令。
现有的数据流分析,一般都可以识别到分支操作,然后执行到分支完毕时,执行一个 merge 的操作,然后继续执行。如上,name 在分支结束后,内容是 {System.getProperty("name")}∨{zhangsan},如果是考虑污点分析的抽象值,则为 {Tainted}∨{NotTainted}={Tainted,NotTainted},然后 sql 被污染,最后发生一个 sql 注入问题(一般静态代码分析,都是 sound 分析,所以会报一个缺陷)。这种是不考虑路径敏感的场景。
上面,不考虑分支条件的时候,对代码片段一和代码片段二分析时,都会报出来一个 sql 注入的问题。当带上分支条件时,对于第二种场景,计算约束 constraint({x == -1}∨{x > 0}) 无解,可以知道污点分支走不进去,从而可以知道其实代码片段二是不会发生 sql 注入的,而只有代码片段一会发生 sql 注入。
从上面的分析,路径敏感分析,可以有效降低静态代码分析中的误报,提高分析的准确性。这就要求,在获取每一条分支路径分析时,都需要同时保存分支的条件,然后通过约束求解方法,获取分支可达性,从而降低误报。另外,如果是基于 SSA 形式的分析,一般可以通过在构造 φ 函数时,同时保存分支信息来实现。
当前,很多静态代码分析框架,例如 Java 中 Soot,原生并没有关于路径分支的可达性的计算支持(即非路径敏感分析,《编译原理》中介绍的数据流分析,就是非路径敏感的),所以如果是基于这些框架开发静态代码分析框架,需要考虑路径敏感性分析的实现(基于分支条件的约束求解),但是也需要注意可能的路径爆炸等问题。
上下文敏感(context-sensitive)
上下文敏感,就是考虑函数调用的上下文信息。一个函数可能会被多个函数调用,那么在不同的函数调用它的时候,在传给它的实际参数或当时的全局变量不同的情况下,可能有不同的行为,如下面的一段代码:
1 | public static void main(String[] args) { |
如上所示,getName()方法基于入参的不同,会返回不同的结果,如上面的代码,在第 2 行和第 6 行,获取到的 name1 和 name2 的污点信息不同,当入参为 3 时,返回的是一个从环境变量中获取的污染的数据,到导致 sql 注入,而当入参为-1 时,返回的是一个常量,不是污染数据,不会有问题。
所以,在上下文敏感的分析中,在第 4 行应该报一个 sql 注入问题,而在第 8 行则不应该报 sql 注入问题。而上下文非敏感的分析中,不考虑传入参数的不同,getName() 方法,则全部返回一个 {System.getProperty("name")}∨{zhangsan},从而导致第 4 行和第 8 行都会报一个 sql 注入的问题。
如上分析,上下文敏感分析,可以减少误报,提高分析精度,同时,也对函数建立摘要提出了挑战。上下文,指在分析函数调用过程中,可能影响函数行为的所有的信息,不仅仅包含传递的实参,还包括全局变量、实参类型等信息,根据我们的分析的目标来确定(静态代码分析,在一定程度上,全都需要进行一定程度的抽象,需要根据分析目标,在上下文和结果上进行合理抽象)。
域敏感(field-sensitive)
域敏感,即针对对象属性、容器等数据类型上成员或者元素上面的分析问题。如下面的例子:
1 | public static void main(String[] args) { |
如上面的例子,在第 2 行,name 是污染数据,然后在第 4 行,将 bean 的 name 属性设为 name,将 bean 的 gender 设置为常量 male,从而 bean 的 name 属性是被污染的,gender 属性没有被污染,继续往下分析,在执行 sql1 的第 8 行,应该报一个 sql 注入问题,而在执行 sql2 的第 11 行,不应该报 sql 注入问题。
如果是域敏感分析,可以将污点打在对象的属性上面,从而能够区分上面的场景,只在第 8 行报一个 sql 注入缺陷,而在第 11 行则不会报缺陷,但是如果是域不敏感分析,则无法报准确将污点打在对象的属性上面,从而导致污点被打在对象上,从而导致第 8 行和第 11 行都会报一个缺陷。
域敏感分析,对于面向对象语言的静态代码分析工具的实现,是一种非常重要的基础要求,如果无法实现域敏感分析,则会导致大量的无关的误报问题。当前,很多开源的分析框架,例如 Java 中基于 Soot 的 IDEal,就实现了域敏感的分析(可以参考http://www.bodden.de/pubs/sab19context.pdf,Context-, Flow-, and Field-Sensitive Data-Flow Analysis using Synchronized Pushdown Systems),也有一些静态代码分析工具,将对象的属性延展为普通的变量来实现污点标记。
上面介绍的这种域敏感分析,是静态代码分析工具的基本要求,下面介绍两种域敏感分析,根据我的使用静态代码分析工具的经验,还很少有工具很好地支持了下面的场景,直接看代码:
案例一,List 场景:
1 | String name = System.getProperty("name"); |
案例二,Map 场景:
1 | String name = System.getProperty("name"); |
当前,还没有很好的工具,可以对上面的场景进行区分,如果没有误报的话,对于案例一和案例二,都是第 7 行应该有 sql 注入缺陷,第 10 行没有,但是,当前还没有一款很好的工具(也可能是有,但是我不知道),可以很好地对 List 和 Map 中的 add 和 put 进行准确处理。List 的 add 方法,Map 的 put 方法,都会把污点标记给打到整个容器上。
总结
流敏感分析,针对的是同一个代码块内部的语句的顺序执行的数据流分析的要求;路径敏感分析,针对的是同一个方法内里面,能够区分不同分支的分析要求(数据流分析是路径不敏感的);上下文敏感分析,是针对跨过程调用的时候的数据流分析要求。这三个概念层层递进,都是面向程度执行结构的敏感性要求,是一个静态代码分析工具的基本通用要求,一般的静态代码分析框架,都应该实现这些基本要求。
域敏感,也叫属性敏感,主要针对面向对象语言(包括 C 语言中的结构体等)的一种分析技术,目的是提高静态代码的分析精度,贯穿整个分析过程。实际上,域敏感并不是必须完全需要实现,静态代码分析工具可以基于需要,在不同的层次上实现域敏感,同时,也可以刻意将待分析程序部分内容实现为域不敏感来提高性能(域敏感分析,对分析时间和分析所消耗的内存,都有显著影响)。
流非敏感指向分析
为什么进行流非敏感的指向分析?下面例子来自《论文解读系列–《Flow-Sensitive Pointer Analysis for Millions of Lines of Code》》,做了一点儿改正。
流敏感分析是考虑了每个程序点的独有状态值,即在某条语句之前和之后,可能状态值是不一样的。比如:
2
3
4
5
p = &a;
q = &b;
p = &c;
p = q;如果是非流敏感分析,那么分析结果将是 pts_set [p] = {a, b, c} 对所有位置均成立,显然这是错误的。因为在语句 1 之后,p 只是指向了 a。如果是流敏感分析,那么结果是,对于语句 1 执行后,pts_set [p] = {a}, 在语句 3 执行后,pts_set [p] = {a ,c}, 在语句 4 执行后,pts_set [p] = {a, b, c}。
可以看到,流敏感分析对于程序分析精度的提高是非常有用的。总结: 流敏感和非流敏感的区别在于:流敏感为每个程序点都计算了该点独有的程序状态
但是流敏感分析复杂度高的多,所以进行流非敏感分析常常是进一步分析的基础。接下来的指向分析时
- 不考虑在堆上分配的内存
- 不考虑 struct、数组等结构
- 不考虑指针运算(如*(p+1))
这些限制有利于我们了解最基础的指向分析。
指向分析和别名分析
指针分析 (pointer analysis) 可以主要分成两类:别名分析 (alias analysis) 和指向分析 (points-to analysis),中文语义不是很好区分。
Alias analysis computes a set S holding pairs of variables (p, q) , where p and q may (or must) point to the same location. On the other hand, points-to analysis, as described above, computes a relation points-to(p, x) , where p may (or must) point to the location of the variable x. We will focus our study in this lecture on points-to analysis, and will begin with a simple but useful approach originally proposed by Andersen.
Anderson 指向分析算法
Andersen’s points-to analysis is a context-insensitive interprocedural analysis. It is also a flow-insensitive analysis, that is an analysis that (unlike dataflow analysis) does not take into consideration the order of program statements. Context- and flow-insensitivity are used to improve the performance of the analysis, as precise pointer analysis can be notoriously
expensive in practice.
该算法的指针赋值操作只有四类,而且分别对应的状态转换函数如下图所示。
- 值变量取地址给指针赋值。
- 指针给指针赋值。
- 指针变量取值给值变量赋值。
- 值变量给指针指向的变量赋值。
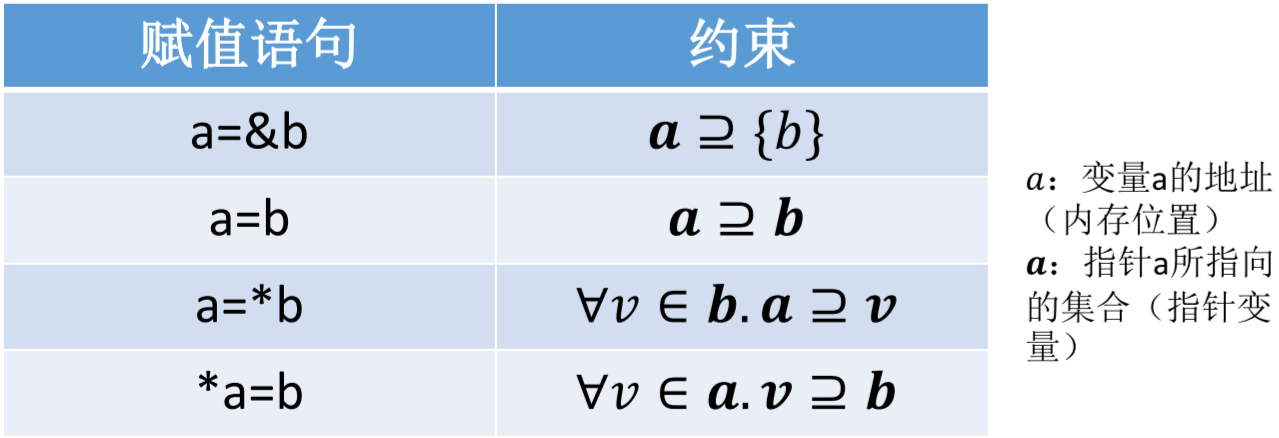
如果读者熟悉 Datalog,以上的约束时很容易实现的。其他所有指针操作都可以分解成这四类操作,例如 **a = &b 等价于c = &b;d = *c;a = *d。
下面详细介绍为什么赋值语句会对应上图中的约束。
1 | z := 1; |
显然打印时,z=2 而不是 1。逐行分解来看,p := &z; 那么 p 就必须包括 z 的所有可能地址,这样才会是 sound 的。
*p := 2; 那么凡是 p 中的元素都可能被赋值成 2,对应第四行。特别是 如果不是一个常数 2,而是一个变量,那么 p 的每一个元素都可能被 b 周的某一个元素赋值,也就是要扩大 p 对应集合的范围,包含 b 对应的集合。
上面 a=*b 也是类似的,a 被 b 中的某个元素赋值,考虑所有可能的情况,就相当于 b 中的每一个元素,都要在 a 的集合中。这里 和 有些混用,可能是为了保持多重指针时的一般性。
总而言之,每次赋值就是扩充被赋值的指针或者元素。
约束求解
请注意它是流非敏感的,所以非常适合 Datalog,读者也会理解下面的例子。

上面右边的约束可以写成标准形式.
涉及到 p 的约束有右边的 3、4、5 行,第 3、4 行很直接,通过并操作限定条件。第 5 行则是间接的,因为 q 里面可能包含了 p,那么 w 可能也会在 p 的范围内。总之,以上的约束都转变成了 p 的扩充。以此类推。
笔者这时也没有对这样的规则感到得心应手,暂且学下去,等深入学习和实际应用之后会逐渐加深掌握的。
之后开始不断计算上述的三个等式,比如 p 变了,那么涉及到 p 的所有等式重新运算,以这样的方式计算直到达到不动点,也就是所有变量的集合都不变了。具体方法是先确定变量之间的包含关系如下图:

但是这里还少了条件下或者说全称量词下的包含关系,那么就要监听全称量词,满足条件则进行对应操作。
后续很多研究进一步优化了指针分析,可以阅读这一篇核心文献:The Ant and the Grasshopper: Fast and Accurate Pointer Analysis for Millions of Lines of Code, Hardekopf and Lin,PLDI 2007
流敏感指向分析
首先,SSA 形式下流非敏感和流敏感是等价的,因为每个变量只会赋值一次,那么就不会存在模糊的指向了。但是之前也提到 SSA 在循环、递归等方面存在局限性,所以流敏感指针分析可以提高精度。流敏感指向分析主要是数据流分析和 Anderson 算法的结合。

前三条操作都比较显然,第四条主要是考虑到 a 实际上只会指向一个位置,那么如果 a 里的元素是多个可能的地址(比如由分支交汇造成的),那么完全替代所有地址对应的集合是不 sound 的,因此多个地址的情况下,采用并集。
后续很多研究进一步优化了指针分析,最新工作采用部分 SSA 来对流敏感进行加速,可 以应用到百万量级的代码,核心论文:Hardekopf B, Lin C. Flow-sensitive pointer analysis for millions of lines of code. CGO 2011:289-298.
指向分析的难点
动态分配在堆的内存
分析堆上分配的内存是一个难点,这种动态分配内存无法知道分配了多少次,比如写在循环里面。那么,一般会做一层抽象,只考虑代码出现的位置,所有循环到这一行代码,都视作同一块内存。因此,编译器处理数组时一般都是把数组当一个节点,而且大多数框架的指针分析算法不支持数组和指针运算。
所以,尽量避免指针运算是一个较好的编程习惯,另外部分语言不支持指针运算,也是有这方面的考虑。
数组和指针运算
简单地说比如 C 语言 支持指针运算,比如 *(p+i) 或者数组 p[i]。这会给分析带来巨大的困难,因为必须要把运算的范围和指针范围结合起来,单独的较为精确的分析已经很复杂了,二者结合极难实现。因此,一般大多数分析框架不支持数组和指针运算。
结构体、对象、容器内的指针
以 C 语言结构体双向链表为例,结构体内的指针和结构体外的指针是不同的,对于两个不同链表,next 这个名字相同的变量也不是代表指向相同的位置。
1 | Struct Node { int value; Node* next; Node* prev;}; |
一般由域非敏感分析和域敏感分析。
域非敏感分析
域非敏感(Field-Insensitive)分析比较简单粗暴,直接忽视结构体、对象自身的辖域。第一个办法是直接把结构体当作是一个整体,结构体里面指针的赋值就当作给结构体赋值,见下图。

第二种办法是不管结构体变量之间的区别了,一视同仁。

域敏感分析

简单地说,就是
- 创建时添加结构体内的指针变量
- 赋值时将结构体拆分成几个字段和结构体变量名。
后续实践时会做这一部分。
基于 CFL 可达性的域敏感分析
回忆 CFL 之前用于函数括号匹配,用来区分不同上下文中的相同函数调用。这里只要将函数这个范围替换成结构体或者对象这个范围即可。

- new 表示新建了指针
- put[f] 表示上一个节点下一个节点内部的值 f (比如结构体内字段) 赋值。
- assign 表示直接赋值
- get[f] 表示从上一个节点取出内部的变量 f 给下一个节点赋值。
从以上的定义,出现了如下的结论:

- 下划线表示逆过程。
*表示前面的部分可以出现一次或者多次。- 变量 A 可以流向 B 的情况只存在于
- 创建变量 A
- 以下两种情况之一。
- 给指针 A 赋值
put[f], A 被赋值给下一个变量 C 的某个字段 f- 变量 D 是变量 C 的别名。
get[f]变量 D 的字段 f 被赋值给 E。
- 重复步骤二,如果最后可以赋值给变量 B,那么表示变量 A 可以流向 B。
- 指向则是与流向是相反的过程。
- 别名则是两个变量既可以指向也可以流向。
如果读者熟悉离散数学的二元关系、等价关系之类的推导,应该能够较快理解以上过程。
从上述步骤可以看到,put[f] 和 get[f] 就相当于之前学习的 CFL 可达性里的括号,只需要沿着括号匹配的方向去构建图。最后可以证明,基于 CFL 和基于 Anderson 算法的域敏感分析是等价的,这里不做证明。
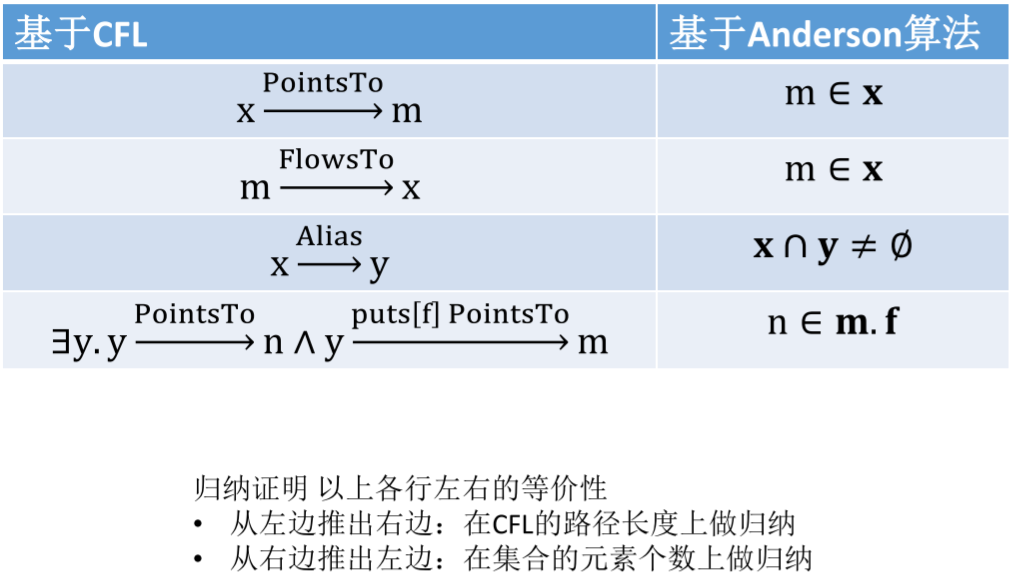
Steensgaard 算法
这个算法的核心是,指针 p 可能指向多个对象,那么就可以把多个对象合并成一个,让 p 只指向一个对象。
1 | p = &x; |
按照 Anderson 指针分析算法,p 指向 x,其他以此类推。r 和 s 是同名,所以可以得到左图图。然后 p 指向了多个对象,那么就把 p 和 q 合并,就变成了右图。
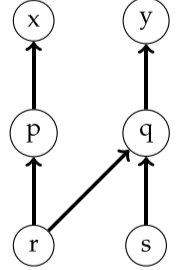

虽然这个过程降低了精度,比如 p 本来不会指向 y 的,s 也不会指向 q 的,不过保证了 sound,不会漏掉原来的情况。合并之后,发现 pq 指向了多个对象,所以还要继续合并。
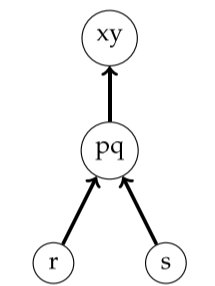
最终,可以表达成如下形式。p 表示地址; *p 表示 p 指向的集合,也就是 p 所有可能指向的对象。join 的意思是把这两个东西合并,如果两个东西是相同的,那么久不用进行任何操作。例如上面的例子中 p q 合并就是因为 s=r,p=&x 就需要把 p 指向的其他东西和 x 合并。依次类推。

只要按照着语句顺序执行下来,那么就不会发生回溯去递归,所以除了合并操作外,线性的复杂度就可以完成。这就不像 Anderson 算法,需要生成约束,然后约束不断迭代,直到不动点。
上下文敏感
这里主要考虑上下文敏感和域敏感指针分析同时出现的情况,我们知道上下文敏感主要是说函数在不同的地方调用,可以通过括号匹配的方式提高精度。上文以提到过,域敏感分析也可以通过 put-get 匹配完成。但是这两者的交集不一定是上下文无关问题,所以同时满足上下文敏感和域敏感是不可能实现的。
可以在两者之间折衷。
降低上下文敏感性
把被调方法根据上下文克隆 n 次。下面的例子中,SetF(y,m) 相当于 m.F=y,但是可以更加抽象化,表示 y 赋值给 m 的 F 域。这里为了方便入门可以改写成更加明显地形式。
1 | y = new A(); |
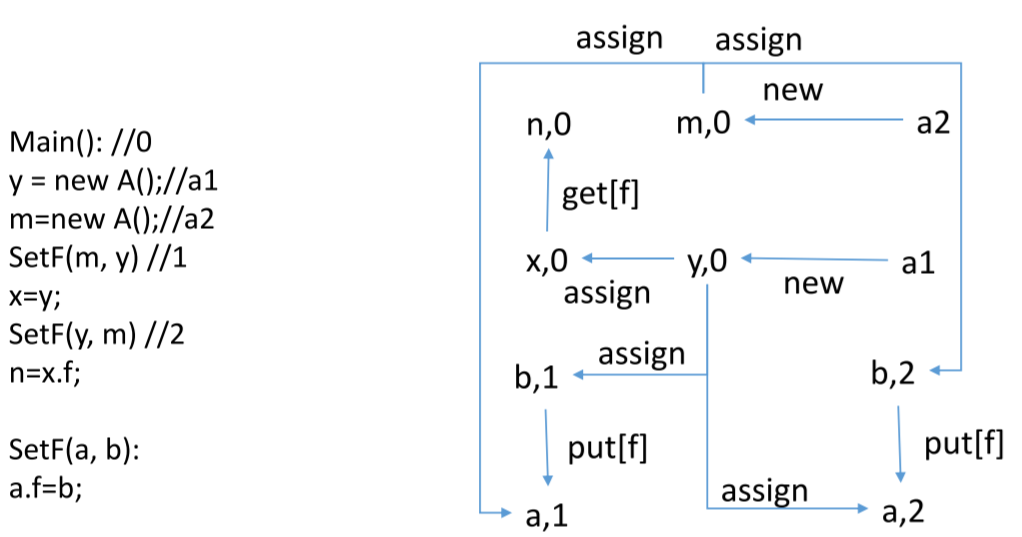
按照之前学习的,可以将 SetF() 函数克隆,第一次调用的参数记作 a,1 和 b,1,第二次调用记作 a,2 和 b,2,这样区别了不同的上下文。其他的 n,0 表示在 Main 函数中的变量。
降低域敏感性
把域展开 n 次,这个想法在链表中体现的尤为明显。
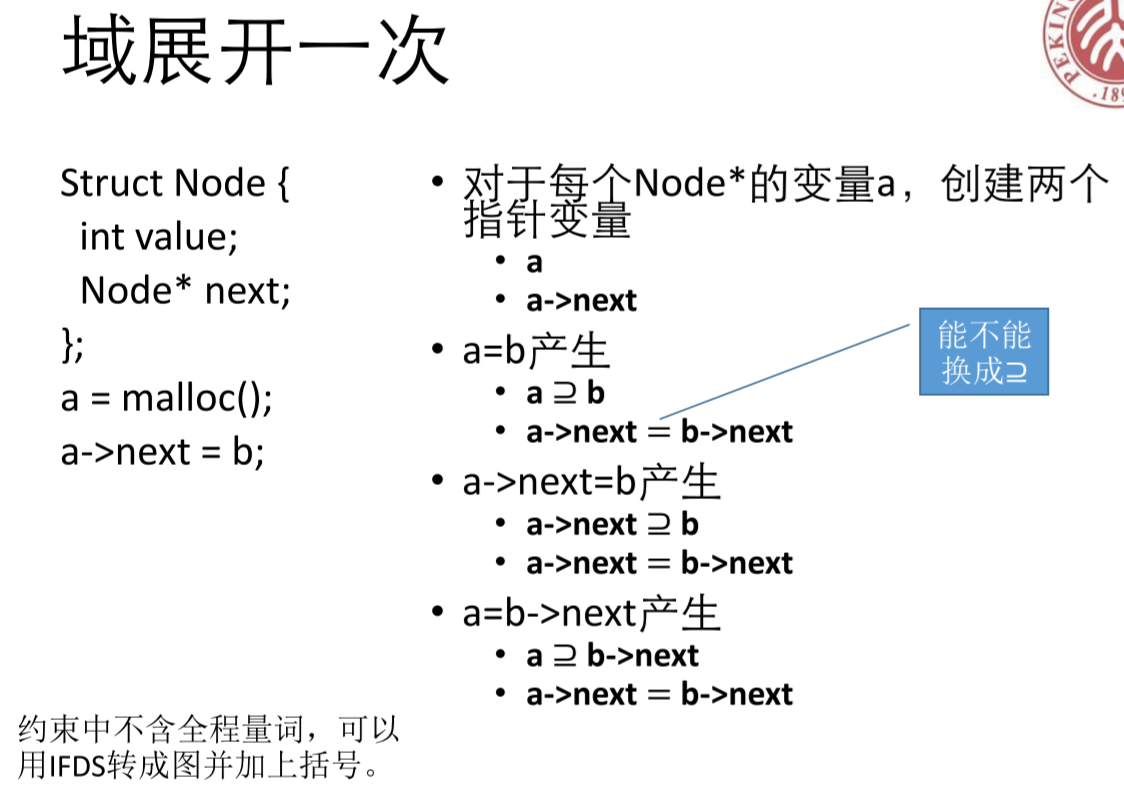
展开的一次的话,就会把 Node* a 这个对象里面的指针展开,当作是与 a 同一个域的变量。然后赋值时,规定对应的约束。注意上面的 = 不是表示赋值,而是表示别名。这样做的理由是为了避免单向指向,导致失去类似于 z= 1;p = &z;*p=2这样间接修改z 的情况。
下面是展开两次的情况:

控制流分析
C 语言和其他某些语言都支持函数指针,这就造成了我们可能并不知道数据流中究竟调用了哪个函数。所以有时候我们并不知道有哪些控制流,更加致命的是一些接口类型或者虚函数,控制流并不直接。因此,我们可以知道指针分析其实是过程间分析中非常重要的内容。
控制流分析就是研究可能的控制流的情况,所以是 may analysis,这里和数据流分析是一样的,都是结果只能比实际的多,但是不能少。控制流分析和数据流分析的关系如下:
- 控制流分析确定程序控制的流向
- 数据流分析确定程序中数据的流向。
- 数据流分析在控制流图上完成,因此控制流分析是数据流分析的基础。
Class Hierarchy Analysis
极其简单,根据函数赋值对象的类型去筛选函数,然后所有筛选后的实现都是可能的,然后把不同实现的返回值合并起来。这种方式极其不精确,一旦实现多了,那么就没用了。

Rapid Type Analysis
这个稍微精确一些,只考虑那些在程序中创建了 的对象,加了一层的筛选。
1 | nterface I { void m(); } |
具体流程如下,初始化两个集合 Methods 和 Classes,记录调用和方法之间的关系集合 Calls->Methods。初始时刻 Methods 只包括 main() 函数,然后开始逐行扫描:
-
如果遇到一个新的方法(相当于函数)的调用
m,那么将在次调用之前,所有实现了这个方法的类加入到Classes集合中。 -
如果
Classes集合中增加了一个类A,那么就把这次调用和类中的方法匹配,也即将1:m()->A.()加入Calls->Methods中。这里的1:m是考虑到上下文敏感性,对不同上下文的调用编号了。 -
将方法
m中的所有方法(例如m嵌套了其他方法n)加入到Methods中,递归地执行第 1 步。
分析速度很快,但是分析的精度优先,如果之前有多个实现,那么就也搞不定了,不过这样的分析实际工程中有所采用。
精确控制流分析
简单地说是一边进行指针分析,一遍进行 control flow analysis (CFA)。这一小部分的内容有些难,暂时跳过。
参考
除了上文每处标出的来源链接,以及这个系列最开始的说明以外,还参考了:
- https://www.cs.cmu.edu/~aldrich/courses/15-819O-13sp/resources/pointer.pdf
- Neil D. Jones, Steven S. Muchnick: Flow Analysis and Optimization of Lisp-Like Structures. POPL 1979: 244-256




