
(三)Datalog和程序分析
前言
笔者在学习 Datalog 之前,已经学习过数据流分析,也学习过一门函数式编程语言,所以能够较为快速地接受新概念。如果读者觉得有些概念比较难以理解,可以搜索关键词学习。
文章引用部分较多中英夹杂,因为没有必要花时间翻译了,我只是在末尾简要用中文提炼我认为的重点,帮助读者理解。笔者没有刻意中英夹杂的意思,提高英文能力对深入最先进的或者较为小领域的知识,是非常重要的。
笔者并没有很扎实的数理逻辑知识,只学过本科计算机专业课离散数学,所以部分概念理解可能不准确。笔者也只是刚入门程序分析,并没有形成整个领域的系统认识,也不了解术语规定。如果发现有任何错误,请不吝斧正。
稳定翻译这篇更加全一些:《Datalog 引擎 Soufflé 指南》
预备知识
逻辑式语言
在之前我们完成了函数式编程 Haskell 的学习之后,开始接触逻辑式编程语言。直接看 wiki 上的介绍:
Logic programming is a programming paradigm which is largely based on formal logic. Any program written in a logic programming language is a set of sentences in logical form, expressing facts and rules about some problem domain. Major logic programming language families include Prolog, answer set programming (ASP) and Datalog. In all of these languages, rules are written in the form of _clauses_:
看起来会和离散数学比较相关,我们这次入手的主要是 Datalog
In ASP and Datalog, logic programs have only a declarative reading, and their execution is performed by means of a proof procedure or model generator whose behaviour is not meant to be controlled by the programmer. However, in the Prolog family of languages, logic programs also have a procedural interpretation as goal-reduction procedures:
其中首先要了解 declarative reading ,declarative programming 没有控制流,只用于描述程序处理特定问题时必须实现的东西,比如 SQL 就是这样的语言。也就是说,datalog 实际上并不是靠程序员控制行为,而是根据命题公式去执行。但是 Prolog 也存在 Procedural programming 范式的过程调用,类似于 C 语言中的函数或者子程序,把一个问题拆分成多个小问题。
The declarative reading of logic programs can be used by a programmer to verify their correctness. Moreover, logic-based program transformation techniques can also be used to transform logic programs into logically equivalent programs that are more efficient.
因此,datalog 这种形式逻辑定义的语言,就很合适用于判断程序的执行是否和期望一致,并 datalog 还支持编译成等价的程序,提高性能。
以上涉及到一些数理逻辑术语,可以查看附录一。
Datalog
wiki 介绍:
It is often used as a query language for deductive databases. In recent years, Datalog has found new application in data integration, information extraction, networking, program analysis, security, cloud computing and machine learning.[1][2]
特点:
- statements of a Datalog program can be stated in any order.
- Datalog queries on finite sets are guaranteed to terminate. This makes Datalog a fully declarative language.
- disallows complex terms as arguments of predicates, e.g.,
p(1, 2)is admissible but notp(f(1), 2) - imposes certain stratification restrictions on the use of negation and recursion. 谓词上的环状依赖不能包含否定规则,简单的说,不管如何推理,不能最终出现 ,这样矛盾的形式。
- requires that every variable that appears in the head of a clause also appear in a nonarithmetic positive (i.e. not negated) literal in the body of the clause。这需要了解逻辑式语言的一般形式,可以见 wiki 最开头的说明。目的就是避免无意义的永真或者永假,或者真值无法通过给出的变量确定的情况。
- requires that every variable appearing in a negative literal in the body of a clause also appear in some positive literal in the body of the clause[5](暂时不懂为啥这么定义)
- Query evaluation with Datalog is based on first-order logic, and is thus sound and complete. 先解释 first-oder logic,中文叫做一阶逻辑或者谓词逻辑。sound 指上近似,程序分析术语,大致意思是按照规则筛选,那么结果一定是复合预期的。complete 指符合规则的一定会被全部筛选出来。
- Datalog is not Turing complete, and is thus used as a domain-specific language that can take advantage of efficient algorithms developed for query resolution.
- Solving the boundedness problem on arbitrary Datalog programs is undecidable,[10] but it can be made decidable by restricting to some fragments of Datalog. 不可判定性的处理,这里 fragment of a logical language or theory is a subset of this logical language obtained by imposing syntactical restrictions on the language.
一个来自 wiki 的例子可以介绍基本的用法和思想:
逻辑式语言例子
These two lines define two facts, i.e. things that always hold:
1 | parent(xerces, brooke). |
This is what they mean: xerces is a parent of brooke and brooke is a parent of damocles. The names are written in lowercase because strings beginning with an uppercase letter stand for variables.
These two lines define rules, which define how new facts can be inferred from known facts.
1 | ancestor(X, Y) :- parent(X, Y). |
meaning:
- X is an ancestor of Y if X is a parent of Y.
- X is an ancestor of Y if X is a parent of some Z, and Z is an ancestor of Y.
This line is a query:
1 | ?- ancestor(xerces, X). |
It asks the following: Who are all the X that xerces is an ancestor of? It would return brooke and damocles when posed against a Datalog system containing the facts and rules described above.
souffle
介绍
开始正式的学习吧,来看看特性
Soufflé is a logic programming language inspired by Datalog. It overcomes some of the limitations in classical Datalog. For example, programmers are not restricted to finite domains, and the usage of functors (intrinsic, user-defined, records/constructors, etc.) is permitted.
One of the major challenges in logic programming is performance and scalability. Soufflé applies advanced compilation techniques for logic programs. We use a range of techniques to achieve high-performance.
declarative rules are efficiently translated to efficient C++ programs on modern computer hardware, including multi-core computers
支持非有限域(关于有限域可以学习近世代数),而且允许过程调用,不要求完全都是声明式。(如果您对这些概念陌生,可以仔细阅读预备知识或者相关 wiki)
用途:
Soufflé was initially designed for crafting static analysis in logic at Oracle Labs. Since then, there have been many other applications written in the Soufflé language, including applications in reverse engineering, network analysis and data analytics.
使用了 souffle 的项目:(可以有一定基础后观摩学习):
Soufflé provides the ability to rapid prototype and make deep design space explorations possible. A wide range of applications have been implemented in the Soufflé language, e.g., static program analysis for Java DOOP, parallelizing compiler framework Insieme, binary disassembler DDISASM, security analysis for cloud computing, and security analysis for smart contracts Gigahorse, Securify, Secuify V2.0, VANDAL. More applications are listed here.
安装
没有看到 windows 版本的直接安装的办法,只能从源码构建,但是比较容易出问题,并且新手难以解决。所以建议使用 linux 系统。按照教程即可。
基础使用
程序示例
以下内容来自官网,表达了传递闭包。
1 | // example.dl |
定义输入
1 | //edge.facts |
详细的命令可以输入 souffle --help 查看。运行之后可以得到输出
1 | souffle -F. -D. example.dl |
但是可能得到的是压缩包,也可能不是:
1 | (base) ➜ souffle_test souffle -F . -D . example.dl |
还需要解压缩就可以查看内容
1 | (base) ➜ souffle_test gzip -d path.csv.gz |
一般情况,可以直接标准输出,即输出的文件夹设置为 -,在控制台打印
1 | (base) ➜ introduction souffle example.dl -D - |
编译
之前是直接以解释器(Interpreter)运行,虽然不需要编译时间,但是效率可能不是很高。可以编译成 C++后运行。souffle -F . -D . -o example example.dl 之后就会生成 cpp 源码和二进制的 cpp 文件。可执行文件也有 help 选项。
-c 的功能和 -o 类似,差别在于 -c 会在编译之后,立刻执行程序。
1 | (base) ➜ souffle_test ./example --help |
调试和日志分析
生成 html 调试日志 souffle -F . -D . -r example.html example.dl,有非常详细的分析报告。
也可以简要生成日志,然后用附带的专门的分析工具 souffleprof 分析性能.
1 | (base) ➜ souffle_test souffle -F . -D . -p example.log example.dl |
其他功能
所有的选项如下表,还是挺丰富的。一些高阶选项后面会接触,大家可以现在都看一遍。
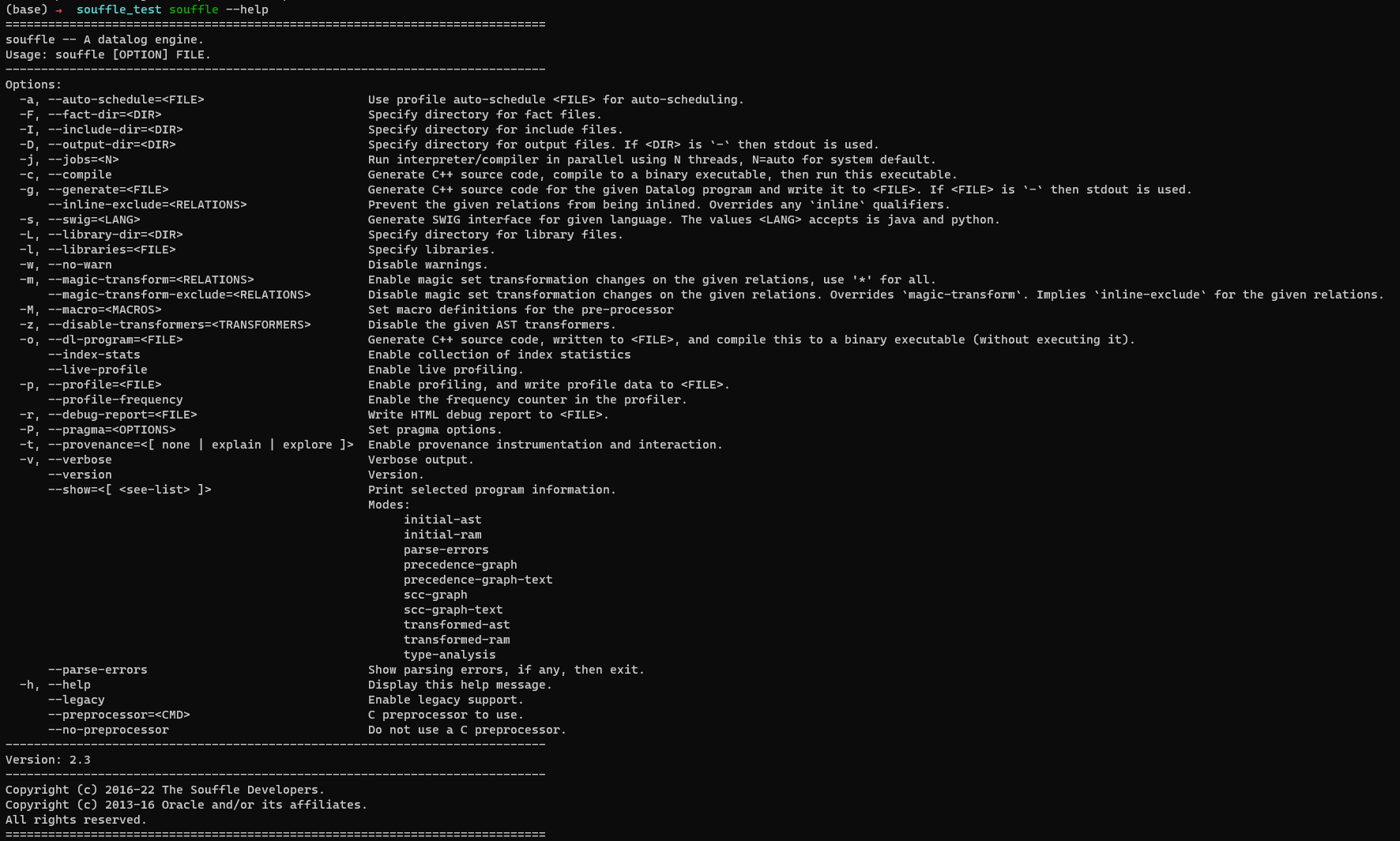
语法
先看一般的介绍:
Facts are just atomic formulas, rules are atomic formulas followed by a condition — one or more atomic formulas conjoined. Explicit disjunctions are not needed. A question consists of one or more atomic formulas conjoined.
Atomic formulas consist of a predicate, optionally followed by a parenthesised list of one or more parameters separated by commas.
Parameters are individual constants — now called names, starting with a lowercase letter, or they are individual variables — or just variables, starting with an uppercase letter. Names have their obvious meaning, whereas variables are either quantified — in facts and rules, or they are to be bound in queries.
请注意用于数据库查询的 datalog 和用于程序分析的 datalog 有一些差别。数据库查询的方面,有个不错的博客。
There is no unified standard for the specification of Datalog syntax. Thus, each implementation of Datalog may differ. A principle goal of the Soufflé project is speed, tailoring program execution to multi-core servers with large amounts of memory.
文件名一般是 <program.dl>,语句并不是顺序执行,程序的整个组成部分如下,有个大致印象即可:

注释
注释的格式和 C 语言完全一致。// 或者是 /**/
数据类型
静态类型系统。只有四类基础类型,symbols 相当于字符串,number 是数字。unsigned 和 float 用的较少。
number 可以是 10 进制,2 进制,16 进制。
1 | .decl A(x:number) |
IO
facts 可以直接写在程序里,也可以通过 .input 从文件读取,默认的间隔用 TAB,输入的文件名字必须和 .decl 名字相同,而且后缀是 .fact
一阶逻辑
:- 是逻辑推导的符号,表示 .decl 定义的关系之间的联系,而且定义方式相当自由,允许递归等形式,但是不能是互相矛盾的式子。
数据结构
一般默认关系的数组结构是自然平衡树 btree,也可以强制地显式指定
1 | .decl A(x:number, y:symbol) btree |
另外也存在特殊地用于数据密集型地数据结构 Brie,这是一种特殊的 Trie,默认读者熟悉前缀树。
1 | .decl A(x:number, y:symbol) brie |
等价关系
默认读者熟悉等价关系,可见 wiki。等价关系非常常用,所以加了特殊的关键字 eqrel,下面给两个程序是等价的:
1 | .decl eqrel_fast(x : number, y : number) eqrel |
1 | .decl equivalence(x:number, y:number) |
inline
和 C 语言类似,inline 将会在评估的时候直接展开,而不是单独的存储数据。
1 | .decl natural_number(x:number) |
相当于下面的
1 | .decl natural_number(x:number) |
这样子会避免计算并且存储大量的 natural_pairs。但是可以知道,这必然会带来一定用法上的限制,我们暂时略过。
析取
一般来说,Datalog 都是采取合取,但是也支持析取的语法。也就是 yong ; 而不是 , 间隔。
例如,假设对于是否能进入房子分成三类人,Housemate 和 Owner 可以进入,但是 Stranger 不可以。就可以得到下面的程序。
1 | .type Owner <: symbol |
算术表达式
souffle 做了一定的函子拓展,支持部分内置算术表达式。例如,可以在推导时加上条件
1 | .decl A(n: number) |
算术操作
- Addition:
x + y - Subtraction:
x - y - Division:
x / y - Multiplication:
x * y - Modulo:
a % b - Power:
a ^ b - Counter:
autoinc() - Bit operations:
x band y,x bor y,x bxor y, andbnot x - Logical operations:
x land y,x lor y, andlnot x
算术比较
The following arithmetic constraints are allowed in Soufflé:
- Less than:
a < b - Less than or equal to:
a <= b - Equal to:
a = b - Not equal to:
a != b - Greater than or equal to:
a >= b - Greater than:
a > b
内置函子
比较特殊的是,autonic() 函子,相当于创建随机数。
ord() 会生成此程序中这个 symbol 类型的序号,比如 a 的序号应该小于 b。
还有一些聚合函数,聚合函数的概念在数据库中应该学习过,就是一个集合中提取出来一个信息。
cout: 统计满足条件的 fact 个数,基本语法是 count:{集合与条件}
1 | .decl Car(name: symbol, colour:symbol) |
max: 很好理解,注意还要制定选择哪一个变量。
min: 和 max 用法完全相同。
sum: 也需要指定变量。
三者的用法见程序:
1 | .decl A(n:number, w:symbol) |
得到的输出如下:
1 | (base) ➜ exp1 souffle max-min-sum.dl -D - |
contains(string1, string2) : string2 是否包含 string1
match: 含有通配符的匹配,但是文档里没有说明有哪些通配符,读者暂时只记住下面的例子即可。
1 | .decl inputData(t:symbol) |
自定义数据类型
基本语法
主要类似结构体,这虽然会影响性能,但是拓展了可用性。基本语法如下:
1 | .type <name> = [ <name_1>: <type_1>, ..., <name_k>: <type_k> ] |
看下面的例子
1 | // Pair of numbers |
也可以定义类型别名:
1 | .type myNumber = number |
特殊地,还存在子类型,每个子类型都是原来类型地严格子集。
1 | .type EvenNumber <: number |
为什么要存在子类型呢,因为这样可取区分不同的类型,比如 EvenNumber 和 OddNumber 就区分开了,在大型的项目中有利于减少错误。
实际的存储方式其实是通过记录 p 然后映射
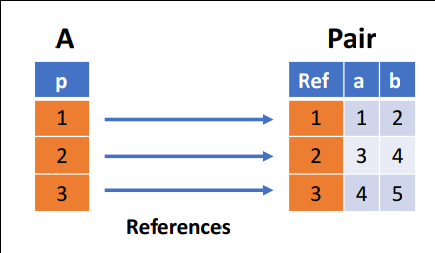
Union 类型
这类似于模式匹配,或者说 C 语言的联合体。具体语法:
1 | .type <ident> = <ident-1> | <ident-2> | ... | <ident-k> |
例如地点可以分成多种类型
1 | .type City <: symbol |
定义的时候,需要注意,所有类别都应该是同一种基础类型,比如上面的 City、Town、Village 都是基础类型 symbol 的子集。
前面提到了子类型,那么就要注意类型的默认转换规则,子类型或者同样的类型,才可以赋值,比如 B=>A 中,A 中 x 的参数类型必须包含 A 中 x 的类型,才可以给 A 赋值。
1 | .type even = number |
如果是这样就会报错.
1 | .type even <: number |
类型转换,但是 as(<expr>, <new-type>) 可以进行类型转换。
1 | .type even <: number |
代数数据类型
他就更加类似模式匹配了,如果模式匹配不熟悉,可以稍微了解 Haskell,博客中也有所涉及。基本语法:
1 | .type <new-adt> = <branch-id> { <name_1>: <type_1>, ..., <name_k>: <type_k> } | ... |
例如,不同的代数数据类型,甚至可以表示简单的数的操作,逐渐有其他语言中 class 类型的味道。
1 | .type T = A { x: number } |
上面 使用的是 Empty 表示空,因为不能够出现 nil。
使用的时候,采用这样的格式 $branch_constructor(args...) 指定选择哪一个分支。每个分支的名字在整个程序的范围内,都必须不能重复。
1 | .type Expression = Number { x : number } |
结果如下
1 | (base) ➜ exp1 souffle test.dl -D - |
递归类型
既然可以使用结构体了,那么就看看能不能支持递归,比如链表和二叉树可以视作是递归类型,但是由于命令式编程语言一切都可以用内存去理解,所以往往不会那么直接的视作递归类型。
例如下面的代码,核心看递归的层面,满足 L 的 fact r1,且 r1 中的 x 小于 30,那么就存在新的 L 的 fact L([r1,x+10])。这里需要注意,r2 可能并不是一层,可能是嵌套的 IntList 类型。
最后,Flatten 把每一个 IntList 中的 x 提取出来。上面提到了 p=>Pair 的映射,所以根据编号,也是有顺序的。
特别注意, nil 类型,用于递归类型最初始的情况。
1 | .type IntList = [next: IntList, x: number] |
来看结果:
1 | (base) ➜ exp1 souffle list.dl -D - |
更多的语法知识,可以查看官方文档的语法部分和高级主题部分。笔者将会逐渐深入学习理论,然后开始进行实际智能合约的分析,后续会逐渐完善这个系列。
应用实例
传递闭包和对称
1 | .decl edge(n: symbol, m: symbol) |
输出结果如下:
1 | (base) ➜ exp1 souffle test.dl -D - |
寻找深度相同节点
对于一颗树,寻找深度相同的节点。
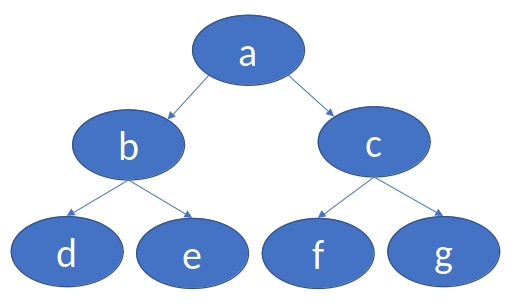
1 | .decl Parent(n: symbol, m: symbol) |
可以发现,推导是允许递归的。
数据流分析
data-flow analysis(DFA),数据流分析基于控制流图,是比较典型的用节点和图表示程序运行过程的分析方法。具体可以见博客的软件分析部分。
这下面是一个可达性分析(也被叫做 liveness 分析,笔者不是很清楚其中区别),可以理解为一个带着分支的循环,d1 和 d2 都定义了变量 v,然后 B3 节点可达的变量 v 一定是在 B4 节点中的 d2。
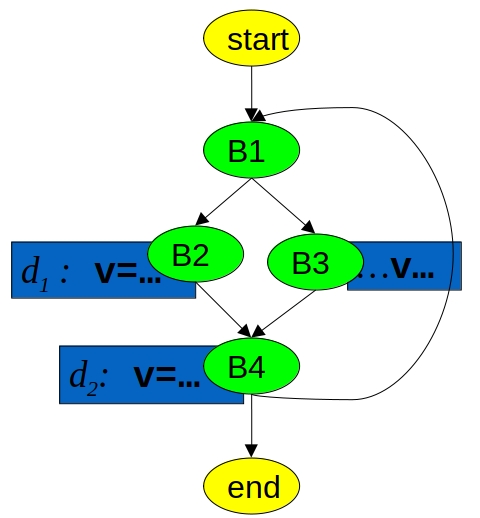
1 | // define control flow graph |
这样,就清楚在每一个节点,某一个变量来自于哪一个定义了。这里必须补充一下,变量并不是和变量名绑定,而是说对应的内存中的对象,如果修改了内存,就是新的对象了,也可以称作是定义。可达性分析可以知道当前语句中的某个变量,来自于哪一个定义的地方。
1 | (base) ➜ exp1 souffle DFA.dl -D - |
偏序关系
Given a set A(x:symbol), create a successor relation Succ(x:symbol, y:symbol) such that the first argument contains an element x in A, and the second argument contains the successor of x, which is also an element of A. For example, the set A = {“a”, “b”, “c”, “d”} would have successor relation Succ=((“a”, “b”), (“b”, “c”), (“c”, “d”)}. Assume that the total order of an element (a symbol in this case) is given by its ordinal number, its internal representation as a number. For example, ord(“hello”) returns the ordinal number of string “hello” for a given program.
题目来自 souffle 官方教程,默认读者已经熟悉前驱、后继关系,其实相当于偏序关系中的大于和小于,但是更加一般化和理论化了。讲解见注释。
更加进一步,我们再去找到最大和最小的元素。可以这样表示最大值,记 $$P:x\leqslant a$$,则
**但是 Datalog 只有存在量词。**根据摩根律推广:

原来的推导等价于下面的 E2:
最小值同理也可得。
感谢这一篇博客帮助我我快速地解决了问题。
所有定义必须大写字母开头
1 | // 定义集合 A, 从文件输入 facts/ |
给定输入的数据 A.facts,注意一个 fact 一行,然后每个 fact 不同的参数用 TAB,不过这里只有一个参数。
1 | a |
结果如下:
1 | (base) ➜ successor souffle successor-relation.dl -F . -D - |
简单指针分析和别名分析
指针分析和别名分析(aliases)有很多相似之处,但是指针分析并不等于别名分析,二者区别如下:
- 指针分析解答的是一个指针可能指向哪个对象的问题
- 别名分析解答的是两个指针是否能指向同一个对象的问题,如果是就认为二者互为别名。
注意,下面的分析都是 may 分析,只是说 可能 指向同一个对象。
需要分析的代码片段如下
1 |
|
详细解释见代码注释,代码执行顺序有非对称的关系就可以了,简单说就是有向图。
1 | .type var <: symbol |
更多的例子见:https://souffle-lang.github.io/examples#defuse-chains-with-composed-types
笔者以应用为主,当学习到对应的部分,就会实现对应的代码。接下来继续学习理论。
参考
- https://souffle-lang.github.io/docs.html
- http://nickelsworth.github.io/sympas/16-datalog.html
- https://qa.1r1g.com/sf/ask/1353816481/
- Datalog and Recursive Query Processing 建议当作工具书去查,除非你要深入研究 datalog
附录一数理逻辑定义
- literal: 原子公式 或者是原子公式的否定式
- clause: 有限的 literal 和逻辑连接词构成的命题公式。
- facts:绝对成立的命题。
- monotonic:因为蕴含而保持“单调的”
- sequent calculi :根据单调关系推导
- Non-monotonic logic:非单调逻辑,简单地说结论不是蕴含关系。
- words: 也叫做 string,也就是一系列的字符。
- letters: 也叫做 symbol,非常基础的东西,可以理解为符号。
- formal language: 由 words 构成的规则集合,words 由 letters 构成,letters 从给定的字符集中选取。
- Well-formed formula: 形式语言字符集中的字符以特定规则构成的有限的命题公式。缩写 WFF。
- sentence: 无自由变量的 WFF。
- Stratification
更多的东西属于数学的范围了,笔者暂时不会深入,因为主要是先用起来再说。





