
Haskell(二)函数式编程
首先,我们需要将自己的编程观念从命令式语言转换到函数式语言上面来。这样做的原因并不是因为命令式语言不好,而是因为比起命令式语言,函数式语言更胜一筹。
基本用法
先看一些简单的程序,了解基本用法。
斐波那契数列:
1 | fab n = if n==1||n==2 then 1 else fab (n-1) + fab (n-2) |
也可以利用模式匹配写成下面的样子,这个类似于分支语句,叫做 Guards
1 | fab n | n==1||n==2 =1 | n>2 = (fab (n-1) + fab (n-2)) |
在 Haskell 中,| 被用于定义函数的多重条件分支。它可以用来在函数定义中指定多个条件,并根据不同的条件执行不同的代码。它的基本语法形式如下:
1 | functionName pattern1 | condition1 = codeBlock1 |
其中,functionName 是函数名,pattern1 是函数的参数模式,condition1、condition2、condition3 等是不同的条件,codeBlock1、codeBlock2、codeBlock3 等是相应的代码块,otherwise 是最后一个条件,用于匹配所有的其他情况。在多重条件分支中,只有第一个匹配的条件的代码块将被执行,其他的条件将被忽略。
where关键字或内置函数,可在运行时用于生成所需的输出,暂存中间的计算结果。当函数计算变得复杂时,这将非常有用。where子句将整个表达式分解成小部分。
do 关键字引入一个块,标识那些带有副作用的代码
求二次方程的根:
1 | roots (a, b, c) = (x1, x2) where |
循环
Haskell 既没有 for 循环,也没有 while 循环,一般用递归来代替。
递归示例 1
例如一个 C 函数,它将字符串表示的数字转换成整数:
1 | int as_int(char *str) |
也可以写成递归的形式:
1 | # |
如果使用 Haskell 递归来实现的话可能会简洁一些。
1 | -- 库函数,字符转数字 |
可以看到,函数式编程语言相比命令式编程语言,提供了截然不同的视角。
这里使用到了 let ... in 关键字,它的含义是在 let 后定义局部表达式,然后在 in 后面用上。可以见 Libby 的回答
ingoes along withletto name one or more local expressions in a pure function.So, to use a simpler example,
2
3
let greeting = "hello" in
print (greeting ++ " world")would print “hello world”.
But you could also use lots of
lets:
2
3
4
let greeting = "hello"
greetee = "world" in
print (greeting ++ " " ++ greetee)And you just need one
inbefore you use the names you just defined.
递归示例 2
考虑以下 C 函数, square ,它对数组中的所有元素执行平方计算:
1 | void square(double *out, const double *in, size_t length) |
这段代码展示了一个直观且常见的 loop 动作,它对输入数组中的所有元素执行同样的动作。以下是 Haskell 版本的 square 函数:
1 | -- file: ch04/square.hs |
可以看到,非常的简洁,因为 Haskell 本身就采用递归的形式去定义列表。
递归示例 3
因为对列表逐元素操作非常常见,所以内置了 map 函数,用法是 map func oprand。比如上一个问题可以写成这样
1 | import Data.Char (toUpper) |
map 函数是一个非常常用的函数,它可以将一个函数应用到列表中的每一个元素,并将结果放入一个新的列表中。map 函数的类型签名和源码为
1 | map :: (a -> b) -> [a] -> [b] |
其中,a 和 b 是任意类型,map 函数接受两个参数:一个函数 f,以及一个列表 xs。它将 f 应用于 xs 中的每一个元素,并返回一个新的列表,其中包含了 f 应用于每一个元素后的结果。
递归示例 4
对列表进行筛选,这也是很常见的,可以实现模式匹配来完成,也就是分支。这里是筛选列表中奇数元素。
1 | oddList :: [Int] -> [Int] |
Haskell 也内置了过滤的函数 filter,从下面的例子也可以看出用法,它可以将一个谓词函数应用到列表中的每一个元素上,并返回一个新的列表,其中只包含满足谓词条件的元素。函数签名和源码如下:
1 | filter :: (a -> Bool) -> [a] -> [a] |
1 | oddList xs = filter condition xs |
递归示例 5
折叠函数也是非常常见的,也就是每次取出列表的第一个元素,然后不断累积。因此,可以写出递归的形式:
foldl func initial_value list,func 是对每个元素怎么操作,其中func 需要是接受 a, b 返回 a 的函数 initial_value 是初始的累加值,list 是被折叠列表。
1 | foldl :: (a -> b -> a) -> a -> [b] -> a |
所以,字符串转数字可以更加简洁。step 函数必须是两个参数,第一个参数是累加值,第二个参数是列表中取出的元素。
1 | import Data.Char (digitToInt) |
再比如列表求和也可以写成
1 | sumList xs = foldl step 0 xs |
也可以简单的写成
1 | sumList xs = foldl (+) 0 xs |
也就是只需要定义累加值和元素的操作即可。
除了左折叠,也有右折叠 foldr,用法是相同的。
但是不推荐使用foldl,因为 Haskell 采用惰性求值(或者叫 非严格求值),不到最后一刻就不会求值,会把大量的表达式存储在内存中,可能造成内存泄漏。而且效率也不高。
1 | foldl (+) 0 (1:2:3:[]) |
每个表达式都保存在一个块中,这么多表达式嵌套,内存消耗会比较大,远不如直接进行数值运算。比如,内置的函数会显示堆栈溢出,而优化后的函数可以快速求解:
1 | Prelude> foldl (+) 0 [1..100000000] |
匿名函数
有时,我们需要编写一个在应用程序的整个生命周期中只能使用一次的函数。为了应对这种情况,Haskell 开发人员使用了另一个称为 lambda 表达式或 lambda 函数的匿名块。Lambda 函数由\字符表示。关于它存在的意义,可以参考 kosmikus 的回答:
Many Haskell functions are “higher-order functions”, i.e., they expect other functions as parameters. Often, the functions we want to pass to such a higher-order function are used only once in the program, at that particular point. It’s simply more convenient then to use a lambda expression than to define a new local function for that purpose.
这里高阶函数的意思是,把函数作为参数的函数,前面提到的 map filter 都是高阶函数。例如这里只要大于 10 的偶数,那么直接用匿名函数,就不需要再用 where 去解释说明了。但是 也说明 lambda 函数的定义只能有一条语句。我们在很多情况下都会避免使用 lambda 。
1 | filter (\ x -> even x && x > 10) [1..20] |
匿名函数以反斜杠符号 \ 为开始,后跟函数的参数(可以包含模式),而函数体定义在 -> 符号之后。
例如下面的代码,判断元素是否包含在列表中。isInAny "abc" ["a","xyz","abcd"] 会返回 True。其中 isInfixOf 用于判断一个列表是否是另一个列表的子串,函数签名为 isInfixOf :: Eq a => [a] -> [a] -> Bool,Eq 是一个类型类,它表示可以进行相等性测试的类型。类型类是一组类型的集合,它们共享一些特定的行为或属性,因此可以用相同的函数或操作符来处理这些类型。
import 用于导入其他模块中定义的函数、类型和常量等。导入一个模块时,Haskell 会在当前目录或全局搜索路径中查找指定的模块,并将该模块中的所有可见定义导入到当前模块的作用域中。除了导入整个模块之外,你还可以指定要导入的函数、类型和常量等。
1 | -- 导入 Data.List 模块中的所有定义 |
所以,下面 isInAny 第一个参数是 可以进行相等性测试的列表,第二个参数是 a 的类型为 t 的容器类型,比如 a 的列表就是一个容器类型 。所以 needle 是列表,haystack 是包含了列表的容器,比如列表为元素的列表。isInfixOf :: Eq a => [a] -> [a] -> Bool 需要接受两个列表,表示第二个列表是否包含第一个列表。
1 | import Data.List (isInfixOf) |
isInfixOf:反引号表示标识符转换成二元中缀运算符,也就是参数可以写在两边。
可以写成下面的形式
1 | isInAny needle haystack = any (\s -> needle `isInfixOf` s) haystack |
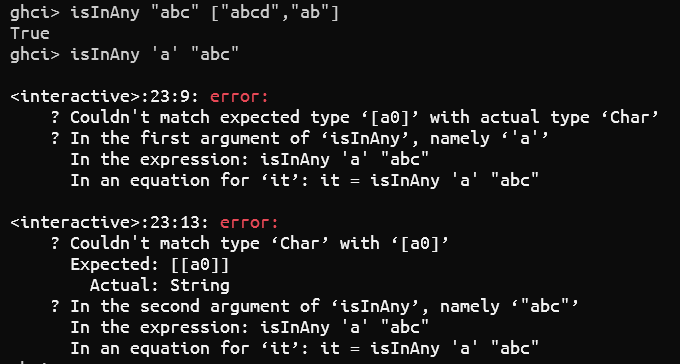
注意 ghci 多行代码的写法,首先是 :{ 换行,然后开始写,最后单独一行 }:,比如下图。
1 | ghci> :{ |
函数柯里化
柯里化:当一个函数有多个参数的时候,先传递一部分参数调用它(这部分参数以后永远不变),然后返回一个新的函数接收剩余的参数,返回结果。
这其实很像链式调用,但是更加灵活。我们曾经提到 a->a->a 表示的是连续的返回值,第一次返回函数 a->a,第二次返回 a。**在 Haskell 中,所有函数都只接受一个参数!**但是为了方便起见,从语法上来说,我们也可以说它接受多个参数。下面看几个例子。
第一个例子
1 | dropWhile :: (a -> Bool) -> [a] -> [a] |
dropWhile是内置函数,第一个参数是条件,第二个参数是列表,遍历列表,从左到右去除满足条件的元素,直到出现不满足条件的元素。isSpace是Data.Char里的函数,判断字符是否是空格。
可以发现,实际上 dropWhile 只接受一个参数,然后接受了之后就变成了新的表达式。a 表示不限制类型,isSpace 作为参数之后,就变成了 [Char] -> [Char]。
1 | *Main> :m +Data.Char |
第二个例子
zip3 函数是将三个列表转换成一个三元组。类型如下,请仔细观察函数类型的变化,可以非常直观地理解柯里化的过程。
1 | Prelude> :type zip3 |
回顾例子
重新回顾我们在匿名函数中讨论过的例子
1 | import Data.List (isInfixOf) |
其中 EQ 类型类用于相等的条件判断,也就是可比较的类型。
The Eq typeclass provides an interface for testing for equality. Any type where it makes sense to test for equality between two values of that type should be a member of the Eq class. All standard Haskell types except for IO (the type for dealing with input and output) and functions are a part of the Eq typeclass.
所以说,isInAny 的参数是可折叠的类型和可以比较的类型。实际上的等价映射是 [a] -> t [a] -> Bool,首先需要一个列表,然后可折叠类型的元素逐个和可比较的类型相比,最后返回布尔值。
又看 any 的类型 any :: Foldable t => (a -> Bool) -> t a -> Bool,发现它是一个可折叠类型;
又看 inSequence 的类型 inSequence :: Eq a => [a] -> [a] -> Bool 是一个做比较返回布尔值的类型。
总之,函数定义的时候可以简化,如果已经高阶函数的函子已经定义了参数,那么定义时可以省略高阶函数的最后一个参数,因为any 已经指定了函数类型了。
1 | *Main Data.Char> isInAny needle = any (\s -> needle `isInfixOf` s) |
节(section)
之前提到过,使用反引号 `` 可以将标识符转换成二元中缀运算符。而节比较特殊,使用括号包围一个操作符,通过在括号里面提供左操作对象或者右操作对象,可以产生一个部分应用函数。具体来说(*3)` 就是部分应用函数,可以实现:
1 | Prelude> map (2^) [3, 5, 7, 9] |
As-模式
1 | suffixes :: [a] -> [[a]] |
As-模式在之前已经学习过了。源码里面用到了新引入的 @ 符号,模式 xs@(_:xs') 被称为 as-模式,它的意思是:如果输入值能匹配 @ 符号右边的模式(这里是 (_:xs') ),那么就将这个值绑定到 @ 符号左边的变量中(这里是 xs )。相当于多了一个参数,从 xs 中拆解出了 xs'。
As-模式还有其他作用:它可以对输入数据进行共享,而不是复制它,减少了内存消耗。
$ 运算符表示右结合,相当于给右边的部分加一个括号,用于简化函数的嵌套调用,比如如何的用法。
1 | -- 括号版本 |
运算符 . 的功能类似,可以将多个函数组合成一个新的函数,将右侧的函数作为左侧函数的参数。这样可以少写几个括号,看起来更加简洁。下面新的函数 h 表示参数先加 1,然后再乘以 2,从而得到一个新的输出结果。
1 | -- 定义一个函数 f 和一个函数 g |
严格求值
严格求值就是非惰性求值,它解决了暂存大量的表达式造成堆栈溢出的问题,但是如果不适当地使用,会增大计算量。
之前地例子是 foldl 非严格求值,而 foldl' 是严格求值。seq 函数是比较典型地严格求值的例子。我大致的理解是,
(seq a b)it evaluates the first argument
ato weak head normal form (WHNF). The only guarantee given byseqis that the bothaandbwill be evaluated beforeseqreturns a value.——https://hackage.haskell.org/package/base-4.17.0.0/docs/Prelude.html#v:seq
也就是说,在返回之前它会把第一个参数求值,直到满足 WHNF,但是不一定 a 比 b 先求值。比如如果 a 依赖 b,那么就可能是 b 先求值。
WHNF 是什么呢?可以参考下面的回答:
Normal form: An expression in normal form is fully evaluated, and no sub-expression could be evaluated any further (i.e. it contains no un-evaluated thunks).
Weak head normal form: An expression in weak head normal form has been evaluated to the outermost data constructor or lambda abstraction (the head). Sub-expressions may or may not have been evaluated. Therefore, every normal form expression is also in weak head normal form, though the opposite does not hold in general.
来看一个例子:
1 | myFoldl f a [] = a |
seq 让 let a' = f a x in a' 严格求值。
斐波那契数列的优化
这一部分会学些一些编码技巧,斐波那契数列最直观的逻辑如下,但是函数对应的值是不会缓存的,所以会具有指数级复杂度。
1 | fibOriginal :: Int -> Integer |
我们考虑缓存中间结果,这样就可以节省计算量。cache 是一个列表,缓存了结果,如果缓存了特定的位置,那么就求值,否则这个位置是 Nothing。
1 | fibList :: Int -> Integer |
但是普通列表更新数据地复杂度是 n,很慢。换成映射会快许多。cache 就是 Map 类型。
1 | import Data.Map (Map) -- 只导入 Map 类型。 |
当然也有 Array 类型,可以完成类似地功能。但是性能不太好
1 | fibArray :: Int -> Integer |
另外一种写法则是利用惰性求值和 memorization
1 | fibList :: [Integer] |
对比的结果如下:
1 | ghci> fibOriginal 25 |
fibOriginal:编译器有优化。fibList:每次都要遍历列表,表现差fibArray:更新时要复制整个数组,导致较高的内存消耗。fibMap:这是使用Data.Map的实现,它是一个平衡二叉搜索树。Data.Map的更新操作通常比数组更新更高效,因为它可以重用未更改的部分。此外,查找操作也非常快,性能接近 O(log n)。fibBest:则使用了惰性求值和 Memorization,而且也用上了内置的优化。
模块
模块是组织和管理代码的基本单位。模块可以包含函数、类型、变量等定义,并将它们导出到其他模块中供使用。模块还可以导入其他模块中的定义,并在自己的代码中使用它们。
要定义一个模块,需要使用 module 关键字,后面跟着模块的名称和导出的定义列表。例如:
1 | module MyModule ( |
在这个例子中,我们定义了一个名为 MyModule 的模块,并导出了一些定义,包括一个函数 someFunction、一个类型 someType 和一个变量 someVariable。这些定义可以在其他模块中使用,但如果没有在导出列表中明确导出,它们将无法访问。
下面是一个简单的 Haskell 模块,包含了一些常用的字符串操作函数,如splitOn(用于根据指定的分隔符将列表分割成子列表)、joinWith(用于连接子列表)、startsWith、endsWith(分别用于检查列表是否以给定的前缀/后缀开始/结束)、toLowerStr、toUpperStr(分别用于将字符列表转换为小写/大写)以及trim(用于删除字符列表前后的空白字符)。
1 | module StringUtil |
测试的结果如下:
1 | ghci> :load str.hs |
最后的话
前面已经介绍过基础知识了,读者已经有了自己深入学习的基础。如果希望能够实际写出程序,那么可以完成Learn4Haskell,学习自定义类型、typeclass 和 instance、newtype、带参类型、Externtion、Functor、Applicatives、Monads。
我这里会给出一些经验。
-
where子句中的模式匹配应该使用case语句,而不能直接在where子句中进行。在where子句中的等式左边不能出现模式。下面的例子是错误的,它用分支来代替了模式匹配,但是 where 子句不行。1
2
3
4
5
6
7
8buildWalls city
| canBuildHouse = city {cityCastle = CastleWithWalls name}
| otherwise = city
where
canBuildHouse
| Castle name = totalPeople >= 10
| otherwise = False
totalPeople = sum . map (\(House people) -> people) $ cityHouses city -
匿名函数中可以使用模式匹配,比如
\(House people) -> people就是匹配House类型,提取它的值。提取自定义类型的变量的值的方式,一般采用模式匹配,嵌套就多次模式匹配。函数传参也是获取了一次值。模式匹配的语法如下:-
分开写函数。
1
2
3f :: Int -> String
f 0 = "Zero"
f 1 = "One" -
case .. of ..类型的匹配。case 表达式后面一定紧接一个表达式,不能再用 guard 语法
1
2
3
4
5describeList :: [a] -> String
describeList xs = "The list is " ++ case xs of
[] -> "empty."
[x] -> "a singleton list."
_ -> "a longer list."-
使用
@的模式匹配。注意如果allx@(x:xs)中allx没有用到,建议使用(x:xs)代替。1
2
3
4
5
6longestPrefix :: Eq a => [a] -> [a] -> [a]
longestPrefix [] _ = []
longestPrefix _ [] = []
longestPrefix allx@(x:xs) ally@(y:ys)
| x == y = x : longestPrefix xs ys
| otherwise = []
使用模式匹配的情况有:
- 字面值处理。
- 列表递归,空列表的情况。
- 提取复杂类型或者容器特定位置的值。
- Maybe/Just 类型匹配。
比如我们的例子,可以下面这样写。其中尽量把局部表达式写在子句中,这样变量名可以非常方便的说明逻辑:
1
2
3
4
5
6
7
8buildWalls :: MagicalCity -> MagicalCity
buildWalls city = case cityCastle city of
(Castle name) -> if enoughPopulation then createWalls name else city
_ -> city
where
createWalls name = city {cityCastle = CastleWithWalls name}
enoughPopulation = totalPeople >= 10
totalPeople = sum . map (\(House people) -> people) $ cityHouse city -
-
类型也有自己的类型,可以作为其他类型的参数。比较典型的是容器比如
[]、Maybe、Either1
2
3
4
5
6
7
8
9
10
11
12
13data IntBox f = MkIntBox (f Int)
-- 变成了 MkIntBox Maybe Int
intBoxMaybe :: IntBox Maybe
intBoxMaybe = MkIntBox (Just 42)
-- 变成了 MkIntBox [] Int,也就是 MkInt Box [Int]
intBoxList :: IntBox []
intBoxList = MkIntBox [1, 2, 3]
-- 变成了 MkIntBox Ether String Int
intBoxEither :: IntBox (Either String)
intBoxEither = MkIntBox (Right 10)




