
Linux 基础
Linux 的基本特点
- Linux 严格区分大小写
- Linux 中所有内容以文件形式保存,包括硬件设备
- Linux 不靠扩展名区分文件类型(虽然有部分文件有后缀,但是并不是给电脑看的)
- Linux 中所有的存储设备都必须在挂载之后才能使用
目录命令
ls(list)
- -a 显示隐藏文件
- -d 显示目录信息
- -h 人性化显示文件大小
- -i 显示 inode 号(相当于地址)
- root 模式下才有不同颜色高亮,以后看能不能调。
查看目录的隐藏文件:
1 | la |
查看目录详细信息(常用来看看权限):
1 | ls -dl |
查看文件详细信息(常用来看看权限):
1 | ll |
cd(change directory)
- ~ home
- -上次所在目录
- . 代指当前目录
- … 代指上级目录
mkdir(make directories)
- -p 一级一级创建新目录
1 | mkdir -p 目录路径 |
rmdir(remove empty directories)
- 一般不用这个。
- 只能删除空目录
- -p 一级一级删除目录
tree(list contents of directories in a tree-like format)
- 显示目录树
文件命令
cat(concatenate files and print on the standard output)
-
-A 列出所有隐藏的或者特殊的符号,包括回车符$、缩进^I 等
-
-E 列出每行结尾的回车符$
-
-n 显示行号
-
-T 列出缩进^I 符号
-
-v 列出特殊符号
一般用:
1 | cat -n 文件名 |
以下几条用的不多:
more(file perusal filter one screen at a time)
less(file perusal filter one line at a time)
head(output the first part of files)
- -n 显示前 n 行
- -v 显示文件名
tail(output the last part of files)
- -n 显示倒数 n 行
- -f 监听文件新增信息(会随着文件更改而刷新)
ln(make links between file)
- -s 建立软链接(必须写绝对路径)。若不加“-s”选项,则建立硬链接文件。
- -f 强制执行。若目标文件已经存在,则删除后再建立链接文件
硬链接
● 不论是修改源文件,还是修改硬链接文件,另一个文件中的数据都会发生改变。
● 不论是删除源文件,还是删除硬链接文件,只要还有一个文件存在,这个文件都可以被访问。
● 硬链接不会建立新的 inode 信息,也不会更改 inode 的总数。
● 硬链接不能跨文件系统(分区)建立,因为在不同的文件系统中,inode 号是重新计算的。
● 硬链接不能链接目录,因为如果给目录建立硬链接,那么不仅目录本身需要重新建立,目录下所有的子文件,包括子目录中的所有子文件都需要建立硬链接,这对当前的 Linux 来讲过于复杂。
软链接
-
软链接的标志很明显,权限第一个出现 l,而且在显色的情况下变蓝色,也有->指向源文件
-
可以相当于快捷方式来使用,特点非常相似
-
删除软链接,源文件不受影响。删除源文件,则找不到实际数据
-
可以链接目录
-
可以跨分区
创建软链接:
1 | ln -s 源文件名 目标文件名 |
diff
- a:将任何文档当作文本文档处理。(treat all file as text)
- b:忽略空格造成的不同。(ignore-space-change)
- B:忽略空白行造成的不同。(ignore blank lines)
- I:忽略大小写造成的不同。(ignore matching lines)
- N:比较两个目录时,如果文件只存在一个目录中,则另一个目录中视为空文件。(new file)
- r:比较目录时,也递归比较子目录。
- u:使用同一输出格式,不会显示相同的部分。(unified/)
1 | diff 第一个文件名 第二个文件名 |
<表示去除,>表示添加,— 表示分割两个文件。实际上相当于把第三行的 is 替换成 is not。
在第一个文件的第四行后面加上显示出来的 5-6 行(add)
1 | diff -c 第一个文件名 第二个文件名 |
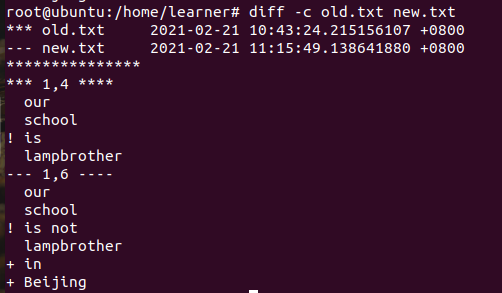
第一部分:***表示第一个文件,—表示变动后的文件。
第二部分***1,4***表示总共有 1,4 行。!表示不同的地方,+表示多出来的地方
1 | diff -Naur 第一个文件名 第二个文件名 |
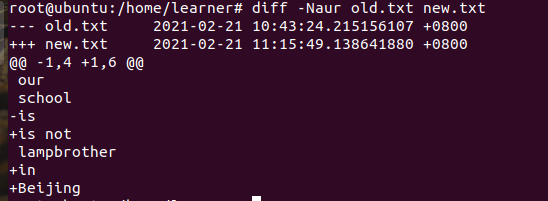
—:表示第一个文件 +++:表示第二个文件。
-1,4 中,'-'表示第一个文件,显示第一行开始的连续 4 行。
只要把 带 ‘-’ 删除,带 ‘+’ 加上,第一个为文件就和第二个文件相同了。
注意:我们一般使用,自动查找不同的地方,生成补丁文件:
1 | diff -Naur 第一个文件名 第二个文件名 >补丁文件名 |
一般补丁文件名设置成以 .patch 或者 .diff 结尾。
打上补丁
1 | patch -pn < 补丁文件名 |
文件和目录命令
du(disk usage)
- a:显示目录及子目录下的所有文件
- h:人性化显示。
查看文件大小:
1 | du -ah 文件名 |
touch(change file timestamps)
- 文件不存在则创建空文件,存在则更改文件或者目录的时间戳(访问时间、数据修改时间、状态修改时间)
- -a 只修改访问时间(Access Time)
- -c 如果文件不存在,则不创建新文件
- -d 把时间戳修改成指定时间
- -m 只修改数据修改时间(Modify Time)
一般创建文件:
1 | touch 文件名 |
stat(display file or file system status)
- 查看文件或者文件夹的访问时间、数据修改时间、状态修改时间、创建时间
- -f 查看所在的文件系统信息。
rm(remove files or directories)
- -f 强制删除(force)
- -i 交互删除,删除前需要确定(默认情况)
- -r 一级一级的删除,删除目录需要加上(recursive)
一般删除文件:
1 | rm -rf 文件名 |
cp(copy files and directories)
- -a:等同于执行-dpr ,如果我们要源文件的属性不要变,完全的复制,这样就很方便。
- -d :如果源文件为软链接,复制之后也为软链接,否则复制的是软链接的源文件。
- -i :交互(interact),询问是否覆盖
- -n:不覆盖。
- -f :强制覆盖
- -l :建立为硬链接文件,而不是复制
- -s :建立为软链接文件,而不是复制
- -p :目标文件保留源文件的属性(创建时间、数据修改时间、状态修改时间等)
- -r :递归复制,复制目录加上
1 | ## 覆盖复制,需要再次确定(常用于恢复备份文件) |
1 | git config --global https.https://github.com.proxy socks5://192.168.0.104:10808 |
mv(move files)
与 cp 用法和效果差不多,主要区别是不保留源文件
- 因为可以设置目标文件名,所以也用来给文件或文件夹改名。相当于剪切。
- -f 强制覆盖。
- -i 交互覆盖,询问是否要覆盖。
- -n 已存在相同名字的文件则不覆盖
- -v 显示移动文件时的详细信息,那些文件有变动。
权限管理命令
了解文件的权限
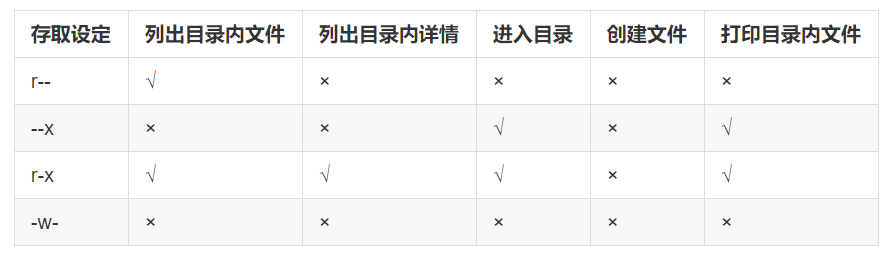
第一列权限位总共有十位
第一位是文件类型,种类比较多
- d:目录文件 directory
- I:软链接文件
- c:字符设备文件
- -:普通文件
后面每三位代表每一类人的权限,分别对应所有者、所属组(授权使用的人)、其他人(其他没有授权的人)
- -r:代表 read,读取权限
- -w:代表 write,写入权限
- -x:代表 execute,执行权限
- -:代表对应位置没有这个权限。
第二列数字对于文件是链接数和 inode 有关
第三列、第四列两个名字分别是所有者和用户组
第五列的数字是文件的大小,单位是 Byte(字节)
第六列日期是最后一次状态修改日期
最后一列是名称,不同的颜色代表不同的类型
权限的具体含义
权限对于文件:
r: 查看。可以用 cat,more ,less,head,tail 等命令查看
w: 可以修改文件内容。但是不能删除文件,需要上级目录有写的权限才可以删除
x: 能否有权限运行。但是还需要看它本身能否正常运行。对于文件,执行权限是最高权限。
权限对于目录:
r: 可以擦好看子目录和子文件,比如 ls 命令
w: 可以修改(新建、删除、复制、剪贴)目录中的子目录或者子文件。比如 touch,rm,cp,mv. 对于目录,写是最高权限、
x: 目录可以执行,代表可以进入这个目录,比如 cd。如果没有可执行权限,那么引用目录的操作不能完成
更加复杂的特殊权限,对于现在而言不必要去学习,以后深入学习操作系统会学到的。
chmod(change file mode bits)
- -R 递归设置,给子目录中的所有文件都设置这个权限
- 选项有三个部分
- 用户身份
- u:user,所有者
- g:group,所有组
- o:other,其他人
- a: all,所有身份
- 赋予方式
- +:加入权限
- -:减去权限
- =:设置权限
- 权限
- r
- w
- x
- 用户身份
示例:
1 | ## 一般用的是:chmod 数字权限 文件名 |
数字权限表达方式(都是八进制的数)
- 4:代表 r
- 2 代表 w
- 1 代表 x
那么这三个数字的 7 种和(没有这个权限记作 0)就唯一代表着一个用户权限的 7 种情况。
例如:chmod u=rwx,g=r,o=- 文件名,就可以记作 chmod 740 文件名
chown(change file owner and group)
- R 递归设置,给子目录中的所有文件都执行这个操作。
示例:
1 | ## 改变所有者 |
chgrp(change group ownership)
chown root 文件名,把所属组改为 root
umask
- 用于设置创建新文件和新目录时的默认权限设置
- 直接输入 umask 返回的时八进制的数 0022,是补码
- umask -S 返回初始权限掩码,u=rwx,g=rx,o=rx。注意 umask 是权限掩码,而不是默认的权限。是八进制的 022 的原码对应的权限
umask 默认权限规则
- 对文件而言,最大权限为 666,没有执行权限,必须手动赋予。
- 对目录而言,最大权限为 777.
- umask 权限为四位的八进制数,默认 0022,第一位为特殊权限,后三位为一般权限(rwx 这种)。
- 计算规则
- 文件最大权限 666,即-rw-rw-rw-,umask 是 022 对应-----w–w-,出去 umask 对应位置出现的字母就可以了。也就是说最大权限减去两者的交集。
- 目录最大权限 777,同样的操作。
帮助命令
man(the system reference manuals)
- f: 帮助的级别(类型)
- k: 和命令相关的所有帮助
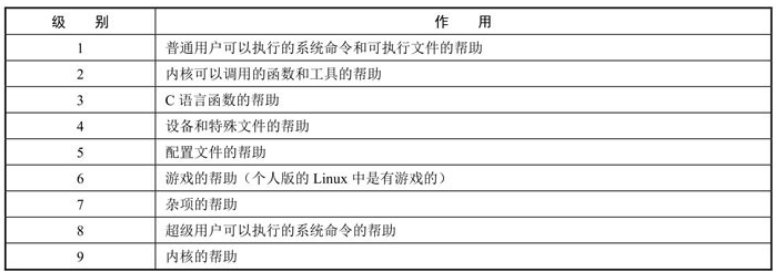
ls(1),代表级别是 1
一般使用:
1 | man 命令名 |
man 内的快捷键:
- g:移动到第一页
- G:移动到最后一页
- /:检索字符。常用 /-选项 查找自己不清楚的选项
- N:检索字符时找到上一个字符串
- n:检索字符时找到下一个字符串
- q:(quit)退出
info(read Info documents)
- 官方的帮助文档大全
info 内快捷命令:
- 回车:进入*(带*的文本表示可查看详细信息)
- u:退出*
- n:进入下一小节
- p:进入上一小节
help
- 只能用于查看 shell 内置命令的帮助
–help 选项:
- 大多数命令种都有这个选项,而且往往简明扼要,很有帮助。
- 一些可执行文件也有这样的帮助。
1 | ##查询命令的帮助 |
搜索命令
注意,在大范围搜索时,搜索命令会给系统带来很大的压力。
whereis
- 用于查看命令的位置和帮助文档的位置

- b:只查看二进制命令的位置
- m:只查看帮助文档的位置
locate(fine files by name)
- i:忽略大小写。
- 由于 locate 命令时搜索 locate 数据库,所以耗费资源少,搜索速度快,但是要重启来更新,所以不包括新建的文件(所以删除后再查看还是可以发现,用 locate 查询后显示存在,但是实际不存在的情况)
- 可以使用 updatedb 更新数据库
- 系统认为某些文件系统或者文件类型和目录(光盘、临时目录、网盘等)是没有必要搜索的,无法用 locate 找到。可在/etc/updatedb.conf 设置
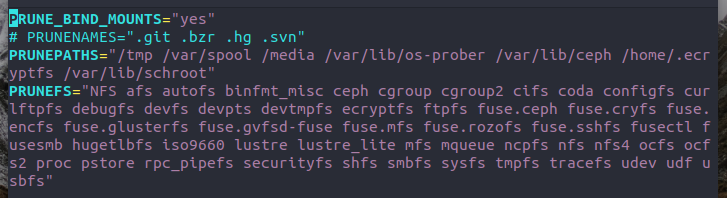
第一行蓝色的:是否开启
第二行蓝色的:排除的目录
第三行蓝色的:排除的文件类型
常用的搜索方式:
1 | ##先更新数据库 |
find
- 功能强大,可以根据时间、权限、大小、inode 对硬盘进行搜索,但是比较消耗系统资源。
- 必须完全匹配才会搜索到,只是包含搜索内容不会被列出
- 格式:find 搜索路径 选项 搜索内容。 例如
按名字或 inode 搜索:
- name:按文件名搜索
- iname:按文件名搜索,不分大小写
- inum:按 inode 搜索。常用于查找硬链接
按大小搜索
-
size -大小:比这个小的文件。
-
size +大小:比这个大的文件。
大小单位如下:
- c:字节
- w:双字节。(因为一个汉字是两个字节)
- k:KB
- M:MB
- G:GB
例如:
1 | find /home -size +10M。 |
按时间搜索
- atime:按访问时间搜索
- mtime:按数据修改时间搜索
- ctime:按状态修改时间搜索
-5:五天内修改的
5:五天前(前 5-6 天)修改的
+5:六天前及以前修改的
例如:
1 | ## 在/home目录下查找数据修改时间在前1天到现在的文件。 |
按权限搜索
- perm:权限恰好相同的文件
- perm -:权限包含于这个的文件(权限比较小)
- perm /:只要所有者、所属组、其他人中有一个或多个满足条件的文件,相当于或。(perm +已经取消了)
例如:
1 | find /home/learner/Interaction/ -perm /743 |
按所有者和所属组搜索
- user:按所有者名查找指定所有者的文件
- group:按所属组名找指定所属组的文件。
- nouser:没有所有者的文件(外来文件,不是在 Linux 里创建或下载的)。
例如:find . -nouser find . -user root
按文件类型搜索
- type d:查找目录。
- type f:查找普通文件。
- type l:查找软链接文件。
例如:find . -type l
逻辑运算多个限定条件搜索
- -a:and 逻辑与
- -o:or 逻辑或
- -not:逻辑非
例如:find . -size +2M -a -type f 查找当前目录大小大于 2MB 的普通文件。
其他辅助命令
- 命令一 -exect 命令二{}\
表示对查找到的命令执行命令二。{}代指命令一的结果。
例如: find /home/learner/Interaction/ -type f -a -iname matplolib -a -size -2M -exec rm -rf {} ; 表示对在/home/learner/Interaction/目录下的叫做 matplolib(不分大小写)的小于 2MB 的普通文件执行 强制递归删除操作。
- ok
ok 的用法和 exec 几乎一样,但是多了一个询问是否操作。
grep
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。用于过滤/搜索的特定字符。可使用正则表达式能配合多种命令使用,使用上十分灵活。
1 | -a --text # 不要忽略二进制数据。 |
规则表达式:
1 | ^ # 锚定行的开始 如:'^grep'匹配所有以grep开头的行。 |
常见用法
在文件中搜索一个单词,命令会返回一个包含 “match_pattern” 的文本行:
1 | grep match_pattern file_name |
在多个文件中查找:
1 | grep "match_pattern" file_1 file_2 file_3 ... |
输出除之外的所有行 -v 选项:
1 | grep -v "match_pattern" file_name |
标记匹配颜色 –color=auto 选项:
1 | grep "match_pattern" file_name --color=auto |
使用正则表达式 -E 选项:
1 | grep -E "[1-9]+" |
使用正则表达式 -P 选项:
1 | grep -P "(\d{3}\-){2}\d{4}" file_name |
只输出文件中匹配到的部分 -o 选项:
1 | echo this is a test line. | grep -o -E "[a-z]+\." |
统计文件或者文本中包含匹配字符串的行数 -c 选项:
1 | grep -c "text" file_name |
输出包含匹配字符串的行数 -n 选项:
1 | grep "text" -n file_name |
打印样式匹配所位于的字符或字节偏移:
1 | echo gun is not unix | grep -b -o "not" |
搜索多个文件并查找匹配文本在哪些文件中:
1 | grep -l "text" file1 file2 file3... |
递归搜索文件
在多级目录中对文本进行递归搜索:
1 | grep "text" . -r -n |
忽略匹配样式中的字符大小写:
1 | echo "hello world" | grep -i "HELLO" |
选项 -e 制动多个匹配样式:
1 | echo this is a text line | grep -e "is" -e "line" -o |
在 grep 搜索结果中包括或者排除指定文件:
1 | # 只在目录中所有的.php和.html文件中递归搜索字符"main()" |
使用 0 值字节后缀的 grep 与 xargs:
1 | # 测试文件: |
grep 静默输出:
1 | grep -q "test" filename |
打印出匹配文本之前或者之后的行:
1 | # 显示匹配某个结果之后的3行,使用 -A 选项: |
压缩和解压缩命令
zip(package and compress files)
- r :压缩目录
- zip 压缩包名 源文件或目录名。 例如:zip -r test_bak.zip test
unzip(extract compressed files in a ZIP archive)
- d:解压到指定位置。
- l:查看.zip 文件
gzip(compress or expand files)
- 用于.gz 格式的压缩或解压缩
- c :保留源文件。格式是:gzip -c 源文件 > 目标文件。例如:gzip -c test >test.gz
- d:解压缩
- r:压缩目录。但是不是压缩目录,而是把目录下的文件逐个打包。
- v:显示压缩文件的信息
- 数字:压缩等级,1-9,数字越大压缩比越大,默认是 6
gunzip
- r:解压缩目录下的所有压缩文件
- 大多数情况下和 gzip -d 差不多。
zcat
- 不解压缩直接查看 .gz 文件
bzip2(a block-sorting file compressor)
- 比较先进,相对较好。
- 不支持压缩目录。
- d:解压缩。
- k:压缩时保留源文件。默认压缩的同时删除源文件。
- v:显示压缩的详细信息。
- 数字:压缩比,1-9。
bunzip2
- k:解压缩时保留源文件。
- 与 bzip2 -d 相似
bzcat
- 不解压缩直接查看 .bz2 文件
tar
- c:打包。
- f:指定压缩的文件名
- v:显示打包过程。
一般使用时 tar -cvf test.tar test,有时打包了之后我们再用 gzip 或 bz2 压缩
解压缩时
- x:解打包
- t:测试(test),即只查看不解打包
- C:指定解打包的位置。
一般使用 tar -xvf test.tar 解压缩
tar -tvf test.tar 查看压缩文件
- z:压缩和解压缩.tar.gz 格式
- j:压缩和解压缩.tar.bz2 格式
实际使用(这才是最常用的方法):
1 | ## 解压缩.tar.gz格式 |
关机和重启命令
sync(Synchronize cached writes to persistent storage)
服务器这条命令很重要,最好手动执行几次
- 将内存中的数据同步到硬盘中
shutdown
- 最安全的开机重启命令
- c:取消设定的 shutdown 命令
- h:关机
- r:重启
定时关机或重启:
方式一:指定时间。shutdown -r 05:30 指 5 点 30 重启
方式二:设定延迟时间。 shutdown -h +10 指十分钟后重启
shutdown -h now 立即关机
用 shutdown -c 取消
reboot
立即重启
下面的都不常用:
halt
poweroff
都是立即关机命令
init
- 数字:调用系统的级别(以后了解)
例如:init 0 调用系统的 0 级别,关机
init 6 调用系统的 6 级别,重启。
网络命令
ifconfig(configure a network interface)
- 用于查看以及修改网卡的 IP 地址和子网掩码
例如:inet 192.168.119.128 netmask 255.255.255.0 inet 是 ip 地址,netmask 是子网掩码。
那么,该设置 ifconfig eth0 192.168.119.128 netmask 255.255.255.0,其中 eth0 指的是设备的编号。
ifup
用于开启网卡 ifup eth0,指开启 eth0 网卡
ifdown
用于关闭网卡
ping
用于主机的通信情况,向网络主机发送 ICMP 请求。
格式 :ping IP 地址
- b:后面加入广播地址,对整个网段进行探测
- c:指定 ping 的次数
- s:指定探测包大小
netstat
- -a:列出所有网络状态,包括 Socket 程序
- -c 秒数:指定每隔几秒刷新一-次网络状态
-n:使用 IP 地址和端口号显示,不使用域名与服务名 - -p:显示 PID 和程序名
- -t:显示使用 TCP 协议端口的连接状况
- -u:显示使用 UDP 协议端口的连接状况
- -1 :仅显示监听状态的连接
- -r:显示路由表
常用一下三个命令:
netstat -tlun
netstat -an
netstat -rn
以下的命令不常用:
write
格式:write 用户名 (然后回车)输入的文本 (CTRL+ D 保存并发送)
wall(write to all)
给所有登录用户发消息。
格式:wall 文本
格式:mail 用户名 (然后出现 subject)主题的内容 (回车)正文(CTRL+D 保存并发送)
单独 mail 表示查看邮件。(有些版本不支持)
Vim 文本编辑器
首先要了解三种模式,可能叫法不同,但是能够识别就可以了。
命令模式
-
按上下左右查看。
-
按 ZZ 快捷退出,但是不会保存文件,不建议这么做。
输入模式
在命令模式下按 i,a,o 等键,就会进入输入模式(底部会出现 INSERT)。可以编辑。
按 ESC 退出到命令模式
编辑模式
在命令模式下按’:‘,即可开始进行指令操作
按 ESC 退出到命令模式
打开文件操作
一般打开文件:
1 | vim 文件名 |
进入到第 n 行:
1 | vim +n 文件名 |
进入到第一次特定字符的位置:
1 | vim +/字符串 文件名 |
光标切换操作
(在命令模式下进行)
- w:移动光标到下一个单词首
- b:移动光标到上一个单词首
- e:移动光标到下一个单词尾
- $:移动光标到行尾
- n$:移动光标到第 n 行行尾
- ^或 0:移动光标到行首
- nG:移动光标到第 n 行行首。在编辑模式直接输入数字,是同样的效果
- f 字符:移动光标到该行指定位置
- %:在匹配的括号切换
搜索命令
在命令模式下,/字符串:向下查询自动跳转到对应字符位置。回车即可完成跳转,删除命令则不跳转。(按下回车后)
- n:向下匹配查找
- N:向上匹配查找
- 注意:1. 可以在编辑模式下输入:set ic 忽略大小写。 输入:set noic 调回来。2. 特殊字符需要转义,例如 \$来搜索$
在命令模式下,/^字符串:搜索行首出现的字符串。
/$字符串:搜索行尾出现的字符串。
编辑操作
- r:在命令模式下,覆盖光标所在的字符,只能是一个
- R:在命令模式下,覆盖光标之后的字符,直到按 ESC 才停止
字符串替换操作
在编辑模式下:起始行,结束行 s/源字符串/替换后的字符串/g
例如:68,72 s/sub1/sub2/g 表示 将 68-72 行出现的 sub1 全部替换成 sub2,g 表示进行不再再次询问确定,c 就是需要再次确认.
1,10 s/^/#/g 表示在 1-10 行的行首添加字符串#,。
删除、粘贴、复制操作
(在命令模式下)
- x:删除光标所在的字符
- nx:删除光标所在以及其后的 n 个字符
- dd:删除光标所在的一行
- ndd:删除光标所在即后面的行,总共 n 行
- uG:删除光标所在行及其后面的所有内容
- D:删除光标位置到行尾的内容
- 在编辑模式下,起始行,终止行 d:删除起始行到终止行的内容。例如:84,86d 指删除第 84 到 86 行
- yy 或 Y:复制这一行
- nyy 或 nY:复制光标这一行及后面的行,共 n 行
- p:把内容粘贴在这行下面
- P:把内容粘贴在这行上面
另外,CTRL + SHIFT C 复制,CTRL + SHIFT D 粘贴
注意:上一步删除的内容可以用于粘贴
u ----(在命令模式下)撤销
保存与退出命令
- w:保存不退出
- q:不保存退出
- !:强制执行。常常用于没有写权限时(readonly)。
常用:wq:保存后退出
w 新文件名:保存到其他地方,这样就保留了修改前的文件。
Vim 配置文件
编辑模式下输入:set nu
可以显示行号,同理:set nonu 取消显示行号。
可以在 ~/.vimrc 设置配置文件,填上自己需要的命令就足够了。
参数非常多,可以用 set all 查看参数。
多窗口编辑
方法一:sp/文件名。水平切分。vs 文件名,垂直切分。
方法二:打开文件时,直接 vim -o 第一个文件名 第二个文件名。
按 CTRL +ww 切换窗口。
输入 r 文件名,即可将一个文件的全部内容复制到这个文件。
定义快捷键
格式:map 快捷键 执行的命令
注意设置快捷键时,CTRL +P,需要按住 CTRL +V,表示这是快捷键,然后再按 CTRL +P 进行设置。
例如:map ^p I#
map ^E a 文本
输入 unmap 对应快捷键 即可取消快捷键。
与 Shell 交互
!命令。可以在编辑模式下使用命令行
r ! 命令。可以把执行的结果加入文件。例如 r ! date 就是加入了时间。
宏记录
在命令模式下,q 宏的命名
进入输入模式,进行更改。
退出到命令模式,按@宏的命名 进行操作。
RPM 包的使用和管理
源代码包
源代码包指 直接是看得见源代码的安装包,需要编译成二进制文件才能够运行。具有如下特点:
主要包括:
- 源代码文件。
- 配置和检测程序
- 软件安装说明。比如 README 或者 INSTALL
优点:
- 开源。意味着如果你有能力,可以自己修改、完善,选择和定制需要的功能,甚至觉得不满意自己可以二次开发。
- 因为是编译后安装,更加稳定,效率更高。
- 卸载无残留。
缺点:
- 安装步骤多,容易出错。
- 编译时间很长。
- 一旦安装出错,必须懂才能够解决,新手的噩梦。
二进制包
已经编译完成,但是也看不到源代码了。主要有 DPKG 包和 RPM 包。Linux 默认使用 RPM 包。
RPM 包的优点:
- 简单,操作不多,只要几个命令。
- 安装速度更加快。
RPM 包的缺点:
- 看不到源代码。
- 依赖性。
RPM 包的有很强大而且方便的管理系统,方便查询、升级、卸载。
RPM 的依赖性
某些软件包,必须要有对应的软件包,才能够正常的安装和使用功能。
依赖分成 软件包依赖和库依赖(属于软件包的一部分,常以 so.1 结尾,需要在www.rpmfind.net 查询所属的软件包)。
RPM 包的命名规则
包的全名:httpd-2.2.15-15. el6. centos.1. i686. rpm
分成 7 部分:
- 软件包名。这里是 httpd
- 软件版本。2.2.15
- 软件发布次数。15
- 软件发布商。el6
- 适用系统。centos
- 适用的硬件平台。i686
- 拓展名。rpm。注意这个是给人看的,Linux 系统本身没有拓展名的要求。
注意区分包名(即上面提到的第 1 部分)和包全名。使用包名是因为已经安装,在数据库里存在。在没有安装之前,都是用包全名。
安装路径

安装命令:rpm
- i:安装(install)
- v:显示详细信息(verbose)
- h:用#显示安装进度(hash)。
- –replacefiles:替换文件安装。如果部分文件已近安装,那么正常安装会因为文件已经存在而报错。使用这个选项可以直接覆盖安装。
- –replacepkgs:重新安装包。不管是否安装过了,都重新覆盖安装。
- –force:强制安装,可以看成–replacefiles,–replacepkgs 的综合。
- –test:测试安装。不会实际安装,只是检测依赖性。
- –prefix:指定安装路径,不建议用,相互调用时要手工设置其他的东西,否则系统不能识别这个包。
- U:升级安装(update)。如果没有安装,就直接安装。如果已经安装的版本低,就升级到新版本。
- F:升级安装(freshen)。如果没安装。就不会安装。也就是说只有较低版本的软件包已经安装了,才能够实行。
一般我们都是直接使用:rpm -ivh 包全名 进行安装。
rpm -Uvh 包全名 也常常使用,效果差不多。
RPM 包的查询
实际上时查询/var/lib/rpm/ 目录里的数据库文件,不能直接用 Vim 查看二进制文件(全是乱码),
格式:rpm - q 包名
- q:查询(query)
- a:所有。rpm -qa 来查看所有的已经安装的包
- i:查询软件详细信息(information)。rpm -qi 包名
- l:列出软件包的安装目录和文件列表(list)。rpm -ql 包名
- p:表示没有安装的软件包。rpm -alp 来查询没有安装的软件包的信息。rpm -qip 包全名 查询没有安装的某个包的信息。
- R:软件包的依赖性。rpm -qR 包名 查询这个包的依赖信息。
RPM 包的卸载
卸载时也要注意依赖性,直接卸载会造成依赖这个包的其他包不能正常使用,直接卸载会报错。
rpm -e 包名 卸载这个包。
- e:卸载(erase)。
- –nodeps:忽视依赖性。不建议这么做。
包的检验和数字证书
RPM 包是否被修改过,或者出现了损坏,到底是哪个文件出问题了。这就靠包的检验了。实际上时把已安装文件和数据库内容进行比较。
rpm -Va
检验所有已安装的包
-
V:检验指定的 RPM 包文件。(verify)
-
Vf:检验是否包修改过
检验结果
验证内容:
- S:文件大小。(size)
- M:文件类型或权限有没有该改变。
- 5:文件的 MD5 校验和是否改变
- D:设备的主从代码是否改变。
- L:文件路径是否改变。
- U:文件的所有者是否改变。
- G:文件的所属组是否改变
- T:文件的修改时间是否改变
文件类型:**
- c:配置文件(configuration file)
- d:普通文档(documentation)
- g:不该在该 RPM 中出现的文件(ghost file)
- l:授权文件(license file)
- r:描述文件。(read file)
校验结果演示:

第一列,没有改变的用 “.” 表示,改变了的显示对应的字母或者数字。
数字证书(数字签名)
上面说的检验方法时依赖安装时自带的文件来校验,如果 RPM 包在安装之前就修改过,那么就必须使用数字证书。
数字证书也叫数字签名,有软件开发者直接发布。只要 RPM 包被更改了,数字证书验证就不会通过。
数字证书的特点:
- 必须找到原厂的公钥
- 安装时会提取 RPM 包的证书信息,然后与发布的数字证书进行校验。
- 校验通过则允许安装,不通过则不允许安装,并且发出警告。
安装数字证书:rpm --import 数字证书名
**查询已经安装的数字证书:**rpm -qa | grep gpg-pubkey
数字证书本身也是 RPM 包,可以用以上的查询命令,如:rpm -qi 数字证书名。也可以用卸载:rpm -e 数字证书名
SRPM 包的使用
SRPM 包没有经过编译,可以查看源代码,但是包装成了 RPM 格式。
命名规则
命名规则和 RPM 基本一致,只是 rpm 变成了 src.rpm
用 rebuild 命令安装
rpmbuild [选项] 包全名
- –rebuild:编译 SPRPM 包,不安装。
- –recompile:编译 SRPM 包,同时安装。
安装目录
会在 /root/rpbuild/ 目录下创建以下文件夹:

用*.spec 文件安装
-
rpm -i *.src.rpm
对于.rpm 文件是安装,但是对于*.src.rpm 文件是解开,放置到 rpmbuild 目录。
rpmbuild 目录下会生成放置源码的 SOURCES 和放置设置文件的 SPEC 子目录。
-
利用 SPEC 目录下的.spec 文件生成 RPM 包。rpmbuild -ba *.spec
- ba:编译,同时生成 RPM 包和 SRPM 包
- bb:编译,只生成 RPM 包。
这两种方法使用一种就可以了。
源代码包的使用和管理
源代码安装的特点
-
可以与 APT 安装的包共存。
-
绝大多数源码包是用 C 写的。
-
源代码包一般从互联网下载。
-
一般是 .tar.gz 或者 .tar.bz2 的压缩格式。
-
约定俗成 /usr/src 保存内核源代码。 /usr/local/src 保存用户下载的源代码。
-
安装的位置一般规定在 /usr/local/各自的软件目录。
-
如果保存比较难解决问题,如果出现 error 或者 warning 表示部分功能不能使用,停止安装则算报错。
安装步骤
首先查看 README 或者 INSTALL 的安装说明
-
下载。要注意匹配的版本。
-
解压缩,移动到 /usr/local/。
-
进入解压缩后的目录,执行 configure,如果没有这个文件,哪个绿色的执行哪一个,进行软件的配置和检查。
1
2
3/.configure --prefix=安装路径
# 或(如果没有configure文件)
/.绿色的哪个文件的名字 --prefix=安装路径 -
进入安装目录,里面有个 Makefile 文件。
1
2
3make
# 如果编译报错,重新编译前要清空头文件,再编译。
make clean -
安装。
1
make install
有些包是可执行文件,不用安装,执行就可以了。
还有很重要的帮助文档
1 | ./可执行文件名 --help |
源码包的升级
对于不用安装的可执行文件,替换就可以了。
对于已近安装的源码包,只要打上补丁,重新编译和安装即可。

源码包卸载
源码包会把所有的文件放在安装的路径下,因此,没有卸载命令,只要删除安装的目录,就可以删的干干净净。
还有脚本安装,运行 .sh 文件,一步一步安装即可
APT 安装工具
Ubuntu 安装软件时,首选这个安装方式。
功能介绍
基本功能:
- 自动从软件源下载最新的软件包以及包含索引和摘要信息的元数据。
- 利用下载好的元数据,完成软件包的搜索和系统的更新。
- 开始安装或者卸载软件包时,自动寻找最新版本,自动解决依赖问题。
软件源和信息来源:
安装和卸载的数据储存在 /var/lib/dpkg/states 文件,它记录着系统已经安装的软件。
查询软件信息和下载软件的软件源在 /var/lib/dpkg/states
解决依赖关系:
大多数情况下依赖的软件包会自动装上,建议安装的软件包会给出提示,但不会自动安装。
如果在软件源中不存在合适的依赖包,就会报错,需要自己解决。
apt-cache
常用 apt-cache 查询软件包的相关信息。用 apt-get 执行软件包安装的相关操作,常常需要使用 root 权限。
显示所有可用软件包:
1 | apt-cache pkgnames |
搜索软件包并列出相关信息:
1 | apt-cache search 软件包名 |
查看指定软件包的详细信息:
1 | apt-cache show 软件包名 |
查看软件包的依赖信息:
1 | apt-cache depends 软件报名 |
查看软件包被哪些包依赖:
1 | apt-cache rdepends 软件包名 |
查看软件的安装状态和版本:
1 | apt-cache policy 软件包名 |
apt-get
- 获得最新的软件包列表,同步 source.list 和 source.lsit.d 中的源索引
1 | apt-get update |
-
升级所有已经安装的软件包及其依赖的软件包,为了确保获得的时是最新的信息,需要执行上一条 update 命令。
1
apt-get upgrade
-
如果想只升级某个软件包:
1
apt-get --reinsatll 软件包名
-
dist-upgrade:如果安装的软件包的依赖关系发生变化,upgrade 命令就不能对它升级,就需要使用这个命令,会自动安装引入的依赖包。
1
apt-get dist-upgrade
-
install:下载、安装、并自动解决依赖关系。
1
apt-get install 软件包名
-
remove:卸载。
1
apt-get remove 软件包名
-
autoremove:自动卸载这个包,并且删除它的依赖的且不再使用的包。
1
apt-get autoremove 软件包名
-
purge:卸载并且清除配置文件。下载的源文件、已经安装的源文件、卸载的源文件都备份在这里。
1
apt-get purge 软件包名
-
source:下载源文件。下载目录在 /var/cache/apt/archives/
1
apt-get source 软件包名
-
clean:删除已经下载的在 /var/cache/apt/archives/ 的软件包,不影响已安装软件的使用。
1
apt-get clean
选项:
-
h:查看帮助文件,超级重要!不记得了命令了,有问题了,先查看这个。
-
s:不实际安装。模拟运行命令。
-
y:不询问,一路 yes 安装下去。
-
u:更新时显示软件包的列表
1
apt-get -u upgrade
配置 APT 的源
用来安装和更新的地址储存在 /etc/apt/sources.list 文件中。而/etc/apt/sources.list.d/ 下的.list 文件使得可以自己定义软件源,这样就能很方便的安装第三方软件。
/etc/apt/sources.list 的结构:
1 | deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse |
第一个字段表示软件包的类型,Ubuntu 一般使用 deb 或者 deb-src,分别表示用.deb 文件安装和用源文件进行安装。
第二个字段定义 URL,便是提供软件源的 URL 地址。
第三个字段定义软件包的发新版本或者类型。
- main:Canonical 支持的开源软件。
- universe:社区维护的开源软件。
- restricted:由设备生产商专有的设备驱动软件。
- multiverse:受版权或者法律保护的相关软件。
- security:重要的安全更新
- updates:推荐的一般更新。
- proposed:预览版的更新。
- backports:无支持的更新,这种更新通常还存在一些 bug。
当打开 URL 地址时,进入 /pool/ 目录会出现
就分别把提供的软件包分成了 Canonical 支持的开源软件、有版权的软件、设备驱动软件和社区维护的开源软件。
Synaptic 包管理工具是图形化的界面,可以比较方便的管理包。
PPA 安装
一般储存在/etc/apt/sources.list.d/ 下的.list 文件
PPA 的语法格式如下:
1 | ppa:user/ppa-name |
添加 PPA 源:
1 | add-apt-repository ppa:user/ppa-name |
删除 PPA 源:
1 | add-apt-repository-r ppa:user/ppa-name |
Deb 软件包的使用和管理
除了 APT 在线软件外,Ubuntu 主要使用 Deb 软件包格式。
-
查询未安装软件包简要信息
1
dpkg -I 包全名
-
查询已安装包的详细信息
1
dpkg -s 包名
-
查询已安装的软件包有哪些文件
1
dpkg -S 包名
-
安装软件包
1
dpkg -i 包全名
-
卸载软件包
1
dpkg -r 包名
-
卸载软件包并删除配置文件
1
dpkg -P 包名
如果是 .rpm 格式,可以把他转化成 .deb 格式,再进行安装
1 | alien rpm 格式的文件名 |
.run 和 .bin 二进制包的安装:
这两种包是由安装脚本和安装程序合成的,安装过程基本一样,我们以.run 为例
-
首先要有可执行的权限。
-
运行该文件。
1
./包的名字
卸载包,到安装的目录里查找,里面会有 uninstall 文件,运行即可。或者安装目录里有 MaintenanceTool,运行。
用户组管理
用户命令
添加一般用户
1 | ## useradd 用户名 |
为添加的用户指定相应的用户组
1 | ## useradd -g root 用户名 |
创建一个系统用户
1 | ## useradd -r 用户名 |
为新添加的用户指定 home 目录
1 | ## useradd -d 指定目录 用户名 |
为新添加的用户自动设置 home 目录
1 | ## useradd -m 指定目录 用户名 |
建立用户且制定 ID
1 | ## useradd 用户名 -u 544 |
修改用户密码
1 | passwd 用户名 |
删除用户
1 | userdel 用户名 |




